
[论文分享] KDD 2025 Proceed:主动式模型适应,应对在线时间序列预测中的概念漂移
| 标题 | Proactive Model Adaptation Against Concept Drift for Online Time Series Forecasting |
|---|---|
| 作者 | Lifan Zhao, Yanyan Shen |
| 机构 | Shanghai Jiao Tong University (上海交通大学) |
| 论文 | https://doi.org/10.1145/3690624.3709210 |
| 代码 | https://github.com/SJTU-DMTai/OnlineTSF |
摘要
时间序列预测在气候、能源、零售和金融等众多领域扮演着关键角色。然而,其始终面临着“概念漂移”(Concept Drift)的严峻挑战,即数据分布随时间演变,导致预测模型性能显著下降。现有解决方案主要基于在线学习,通过不断将近期时间序列观测数据组织成新的训练样本,并根据近期数据的预测反馈更新模型参数。然而,这些方法普遍忽略了一个关键问题:每个样本的真实未来值(ground-truth future values)必须延迟到预测期之后才能获取。这种延迟在训练样本和测试样本之间造成了时间上的“间隔”(temporal gap)。我们的实证分析揭示,这个间隔可能引入新的概念漂移,导致预测模型适应了过时的概念,从而影响了预测的准确性。为了解决这一问题,本文提出了一种新颖的主动式模型适应框架——Proceed,用于在线时间序列预测。Proceed首先估计近期使用的训练样本与当前测试样本之间的概念漂移,然后利用一个适应生成器(adaptation generator)将估计出的漂移高效地转化为参数调整,从而主动地使模型适应测试样本。为了增强该框架的泛化能力,Proceed在合成的、多样化的概念漂移数据上进行训练。在五个真实世界数据集上,针对多种预测模型进行的广泛实验表明,Proceed比最先进的在线学习方法带来了更显著的性能提升,极大地增强了预测模型抵御概念漂移的能力。
1 引言
时间序列预测在现代社会中无处不在,从预测气候变化、能源消耗到零售需求和金融市场波动,其应用范围极其广泛。近年来,深度学习模型在时间序列预测领域取得了显著进展,能够从历史观测数据中学习复杂的模式,并预测未来值。然而,这些模型在实际部署中常常面临一个核心挑战:概念漂移(Concept Drift) 。概念漂移指的是数据生成过程的潜在概念随时间动态变化,导致模型在训练时学到的模式在未来可能不再适用,从而使预测性能急剧下降。
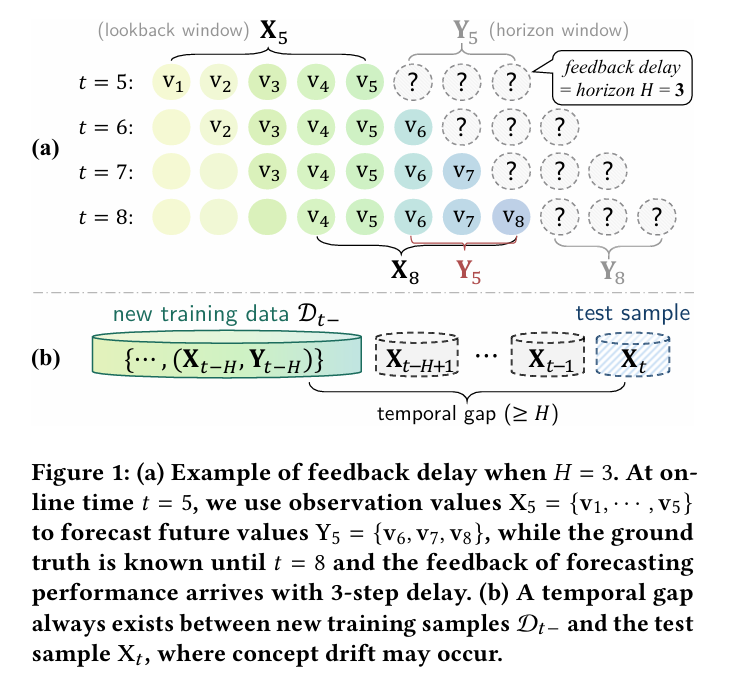
图1:(a) 当预测步长 $H = 3$ 时的反馈延迟示例。在在线时间 $t = 5$ 时,我们使用观测值 $X_5 = \{v_1, \cdots, v_5\}$ 来预测未来的数值 $Y_5 = \{v_6, v_7, v_8\}$,而真实值要到 $t = 8$ 才可知,因此预测性能的反馈存在3步的延迟。
(b) 新的训练样本 $D_{t-}$ 与测试样本 $X_t$ 之间始终存在一个时间差,在这个时间差期间可能会发生概念漂移(concept drift)。
传统的在线学习方法旨在通过持续地将最新观测数据纳入训练集并更新模型参数来应对概念漂移。这些方法通常依赖于对近期数据的预测反馈(例如,预测误差或梯度)来调整模型。然而,本文深入探讨了一个被现有方法普遍忽视的关键问题:预测的真实未来值(ground-truth future values)并非立即可用,而是存在一个固有的延迟,直到预测期结束后才能获取。这种延迟在可用于模型更新的训练样本与当前需要预测的测试样本之间,不可避免地造成了一个时间间隔(temporal gap)。我们的实证分析表明,这个时间间隔本身就可能引入新的概念漂移,导致模型在适应最新数据时,实际上可能适应了时间间隔之前、已经过时的概念,从而无法有效应对当前时刻的真实数据分布。
我们可以将这一挑战类比为一名学生准备考试。如果学生只能根据几周前完成的旧练习题来调整学习策略,而考试内容却在不断更新,那么他很可能无法在最新的考试中取得好成绩。优秀的学习者不仅会回顾旧知识,更会主动预判未来的变化趋势,并提前调整学习方法。SEAL框架受到了这种深层“自我学习”机制的启发,旨在打破LLM的静态壁垒,赋予其主动学习和适应的能力。同样,在时间序列预测中,模型也需要一种“主动预判”的能力,而不仅仅是被动地根据滞后的反馈进行调整。
为了弥补这一“时间间隔”带来的概念漂移问题,本文提出了 Proceed,一个用于在线时间序列预测的主动式模型适应框架。Proceed 的核心思想在于,它不再仅仅依赖滞后的反馈来调整模型,而是尝试在进行预测之前,主动估计当前训练样本与测试样本之间的概念漂移,并据此调整模型参数,从而实现对未来概念的“预适应”。这种前瞻性的适应机制,使得模型能够更好地应对动态变化的环境,显著提升在线时间序列预测的鲁棒性和准确性。
2 方法:Proceed 框架的核心机制——主动式模型适应
Proceed 框架的精髓在于其独特的主动式模型适应机制,它旨在弥补训练样本与测试样本之间的时间间隔所带来的概念漂移。与传统在线学习方法被动地根据滞后反馈调整模型不同,Proceed 能够主动估计概念漂移,并据此调整模型参数,从而实现对未来概念的“预适应”。
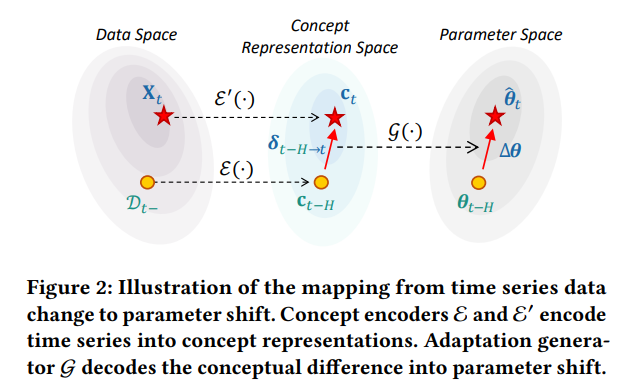
图 2:Proceed 框架概览。Proceed 在预测测试样本之前,主动估计训练样本与测试样本之间的概念漂移,并通过适应生成器将漂移转化为参数调整,从而实现模型的主动适应。
2.1 挑战:时间间隔与概念漂移
在线时间序列预测中,一个固有的挑战是预测值的真实标签(ground truth)并非立即可用,而是存在一个 $H$ 步的反馈延迟。这意味着在时间 $t$ 进行预测时,可用于模型更新的最新训练样本 $\mathcal{D}{t-H} = (\mathbf{X}{t-H}, \mathbf{Y}{t-H})$ 与当前需要预测的测试样本 $(\mathbf{X}_t, \mathbf{Y}_t)$ 之间存在一个至少 $H$ 步的时间间隔。如图 1 所示,这个时间间隔可能导致 $\mathcal{D}{t-H}$ 中包含的概念与 $(\mathbf{X}_t, \mathbf{Y}_t)$ 中的概念存在显著差异,即发生了概念漂移。现有在线学习方法由于未能有效解决这一时间间隔导致的概念漂移,其性能受到限制。
为了量化这种影响,作者进行了实证分析,比较了两种在线学习策略:
- 实用策略(Practical):在时间 $t$ 使用最新的可用训练样本 $(\mathbf{X}{t-H}, \mathbf{Y}{t-H})$ 进行模型更新。
- 最优策略(Optimal):假设在时间 $t$ 可以立即获得 $(\mathbf{X}{t-1}, \mathbf{Y}{t-1})$ 的真实标签(这在实践中是不可行的,因为它涉及未来信息泄露)。
实验结果表明,实用策略的平均预测误差大约是最优策略的两倍,且随着预测视野 $H$ 的增加,性能差距变得更加显著。这强有力地证明了在实用场景中,训练样本与测试样本之间存在显著的概念漂移,并且现有在线学习技术未能充分解决这一问题。
2.2 Proceed 解决方案
Proceed 旨在弥合最新训练数据与测试样本之间的差距,并提升在线时间序列预测在概念漂移下的性能。其核心思想是:将概念漂移映射到参数变化。作者假设概念空间中的漂移方向和程度可以反映参数空间中参数变化的可能方向和幅度,从而指导模型进行适应。具体而言,Proceed 在每个时间步 $t$ 包含以下四个关键步骤:
- 在线微调(Online Fine-tuning):给定一个由 $\theta_{t-H-1}$ 参数化的预测模型 $\mathcal{F}$,首先使用 $\mathcal{D}{t-H} = (\mathbf{X}{t-H}, \mathbf{Y}{t-H})$ 对其进行微调,得到 $\theta{t-H}$。
- 概念漂移估计(Concept Drift Estimation):利用两个概念编码器 $\mathcal{E}$ 和 $\mathcal{E}’$ 分别从 $\mathcal{D}{t-H}$ 和测试样本 $\mathbf{X}_t$ 中提取概念表示 $\mathbf{c}{t-H}$ 和 $\mathbf{c}t$。然后,通过计算概念差异 $\delta{t-H \to t} = \mathbf{c}t - \mathbf{c}{t-H}$ 来估计概念漂移的隐藏状态。
- 主动式模型适应(Proactive Model Adaptation):给定估计的概念漂移 $\delta_{t-H \to t}$ 和参数 $\theta_{t-H}$,Proceed 使用一个适应生成器 $\mathcal{G}$ 来生成参数调整 $\Delta \theta$,从而将 $\theta_{t-H}$ 调整为 $\hat{\theta}_t$。
- 在线预测(Online Forecasting):最后,使用调整后的模型 $\mathcal{F}(\mathbf{X}_t; \hat{\theta}_t)$ 进行预测。
2.3 概念漂移估计
与现有概念漂移检测方法仅估计漂移程度(一个标量)不同,Proceed 提出建模一个高维表示向量 $\in \mathbb{R}^{d_c}$ 来表征概念漂移的程度和方向。具体实现如下:
- 概念编码器 $\mathcal{E}$:从最新的训练样本 $\mathcal{D}{t-H}$ 中提取概念表示 $\mathbf{c}{t-H}$。它通过对每个变量的时间序列应用 MLP,然后取平均来获得一个全局概念表示。
- 概念编码器 $\mathcal{E}’$:从测试样本 $\mathbf{X}_t$ 中提取概念表示 $\mathbf{c}_t$。同样通过 MLP 和平均操作实现。
- 概念漂移向量:通过计算 $\delta_{t-H \to t} = \mathbf{c}t - \mathbf{c}{t-H}$ 得到,该向量捕获了从训练样本到测试样本的概念变化。
值得注意的是,$\mathcal{E}’$ 具有估计 $\mathbf{Y}_t$ 隐藏状态的潜力。当回溯窗口 $L$ 足够大时,$\mathbf{X}_t$ 本身包含一系列视野窗口,$\mathcal{E}’$ 可以学习跨视野窗口的时间演变模式,并推断下一个视野窗口 $\mathbf{Y}_t$ 的隐藏状态。
2.4 主动式模型适应
将概念漂移表示解码为适当的参数变化是一个非平凡的任务,因为参数空间通常维度巨大。为了解决这个问题,Proceed 设计了一个适应生成器 $\mathcal{G}$,它采用瓶颈层(bottleneck layers)来生成少量适应系数 $\alpha^{\ell}$ 和 $\beta^{\ell}$,用于模型的每一层 $\ell$。
具体而言,适应系数通过以下方式计算:
\[[\\alpha_t^{(\\ell)}, \\beta_t^{(\\ell)}] = \\mathbf{W}_2^{(\\ell)^\\top} (\\sigma(\\mathbf{W}_1^{(\\ell)^\\top} \\delta_{t-H \\to t} + \\mathbf{b}^{(\\ell)})) + \\mathbf{1} \\tag{3}\]其中,$\mathbf{W}_1^{\ell}$、$\mathbf{W}_2^{\ell}$ 和 $\mathbf{b}^{\ell}$ 是可学习的参数,$\sigma$ 是 Sigmoid 激活函数。通过共享 $\mathbf{W}_1^{\ell}$ 和 $\mathbf{W}_2^{\ell}$ 跨相同类型的层,并为每层学习独立的偏置项 $\mathbf{b}^{\ell}$,Proceed 大幅减少了适应生成器的总参数量,从而避免了过拟合和内存开销。
最终,用于在线预测的适应参数 $\hat{\theta}_t^{\ell}$ 通过以下方式导出:
\[\\hat{\\theta}_t^{(\\ell)} = (\\alpha_t^{(\\ell)^\\top} \\beta_t^{(\\ell)}) \\odot \\theta_{t-H}^{(\\ell)} \\tag{4}\]其中 $\odot$ 表示元素级乘法。这意味着模型调整 $\Delta \theta^{\ell}$ 是通过将 $\theta_{t-H}^{\ell}$ 与一个由适应系数生成的缩放因子相乘得到的。这种方法避免了直接从概念漂移映射到每个参数的调整,而是选择了一种更精细和高效的策略。
2.5 训练方案:合成多样化概念漂移
为了增强 Proceed 的泛化能力,使其能够处理在线阶段可能出现的新的概念,作者提出了一种创新的训练方案:通过打乱历史数据来合成多样化的概念漂移。如图 3 所示,即使未来的测试样本可能包含分布外(out-of-distribution, OOD)的概念,但它们之间的概念漂移模式可能与训练数据中学习到的合成概念漂移模式相似。通过在这种合成漂移上训练,Proceed 能够学习概念漂移与理想参数调整之间的关系,从而在遇到重复出现的概念漂移时,能够根据经验调整模型。
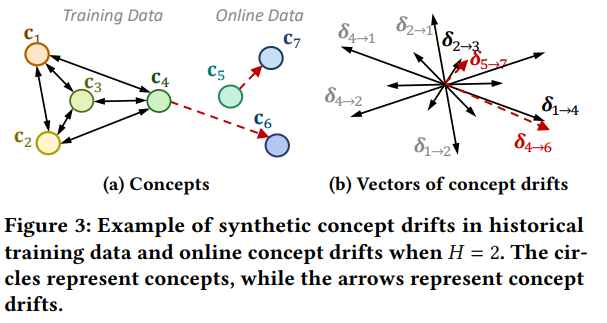
图 3:合成概念漂移示例。通过打乱历史数据,生成多样化的概念漂移,用于训练 Proceed 的适应生成器,使其能够学习概念漂移与参数调整之间的关系。
Proceed 采用小批量训练(mini-batch training)来提高训练效率。在训练过程中,预测模型和模型适应器是联合训练的。然而,在在线阶段,预测模型会进行微调,而模型适应器的参数则保持冻结,因为测试样本的真实标签不可用。
3 实验
为了全面评估 Proceed 框架的有效性和效率,作者在五个真实世界的时间序列数据集上进行了广泛的实验,并与多种基线方法进行了比较。这些数据集包括 ETTh2、ETTm1、Weather、ECL 和 Traffic,涵盖了不同的时间粒度和数据特性。
3.1 实验设置
- 数据集:使用 ETTh2、ETTm1、Weather、ECL 和 Traffic 五个流行基准数据集。数据集按照 20:5:75 的比例划分为训练集、验证集和测试集,以模拟在线学习场景中有限训练数据的情况。
- 预测模型:Proceed 框架具有模型无关性,因此选择了三种流行且先进的预测模型作为骨干:TCN 、PatchTST 和 iTransformer。
- 在线学习基线:将 Proceed 与以下方法进行比较:
- GD Gradient Descent:朴素的在线梯度下降方法。
- FSNet:一种先进的在线模型适应方法,特别为 TCN 设计。
- OneNet:一种基于在线集成的模型无关方法。
- SOLID++:SOLID的一个变体,它持续微调所有模型参数。
3.2 总体比较:有效性
实验结果表明,Proceed 在大多数情况下都取得了最佳性能,显著降低了预测误差。
表 3:不同在线方法在 MSE 上的表现
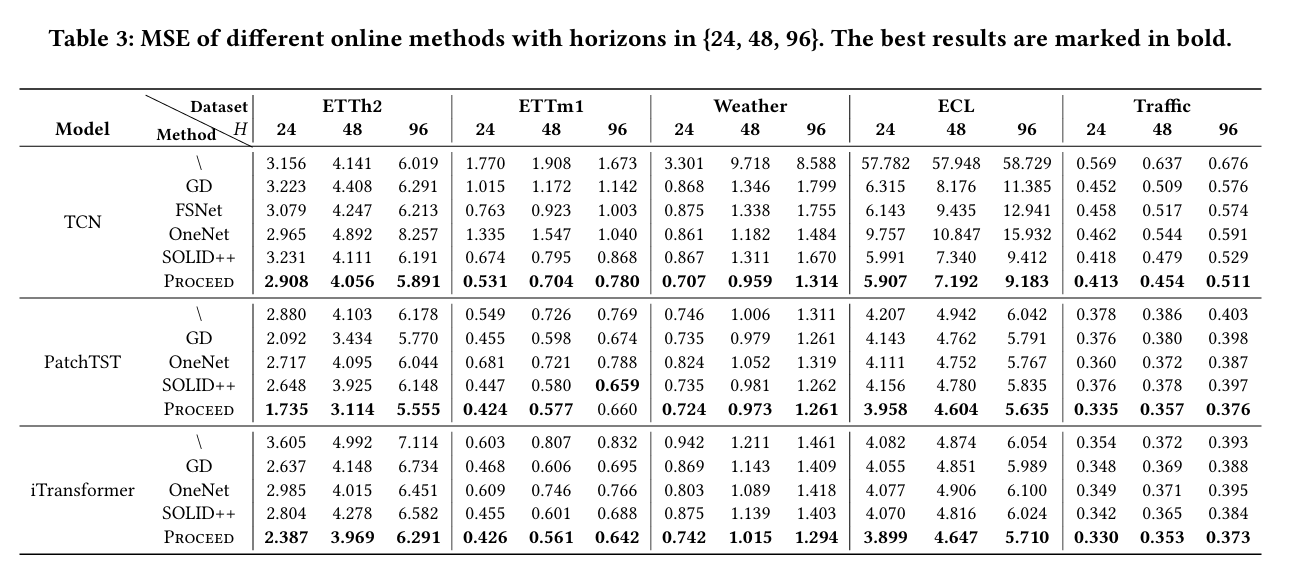
Proceed 展现出显著的性能提升效果,它将未采用在线学习方法的 TCN、PatchTST 和 iTransformer 模型的平均预测误差分别降低了 42.3%、10.3% 和 12.9%。不仅如此,与现有的在线模型适应方法相比,在相同的预测模型基础上,Proceed 的表现也更为出色,其性能相较于 FSNet、OneNet 和 SOLID++ 分别平均提高了 12.5%、13.6% 和 6.7%。更值得一提的是,Proceed 应对概念漂移的能力尤为突出:在概念漂移显著的数据集(如 ETTh2、ETTm1 和 Weather)上,经过其增强的 TCN 模型甚至能够超越未进行在线学习的 PatchTST 和 iTransformer。这些结果充分表明,时间序列预测模型需要通过模型适应来处理复杂的概念漂移,而 Proceed 正是应对这一挑战的有效方法。
3.3 效率比较
除了有效性,效率也是在线时间序列预测中的一个重要考量。作者在 Traffic 数据集上比较了不同模型适应方法的 GPU 内存占用和推理延迟(如图 5 所示)。
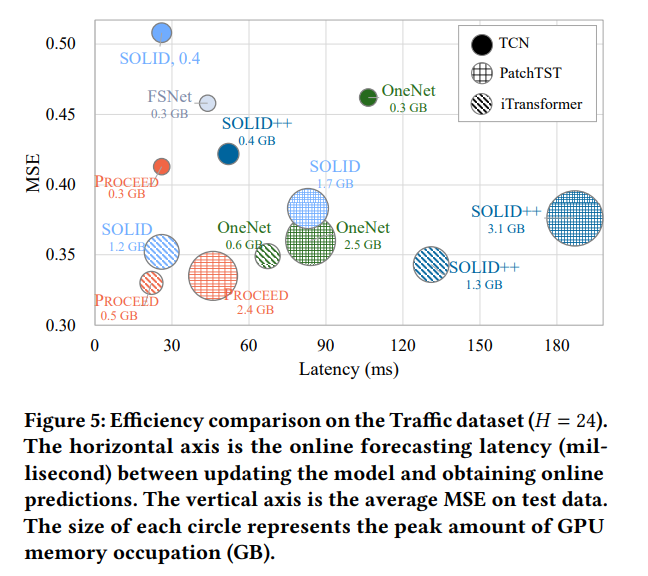
图 5:效率比较。横轴表示在线预测延迟(毫秒),纵轴表示测试数据上的平均 MSE。圆圈大小表示 GPU 内存占用峰值(GB)。
- 低延迟:Proceed 仅使用最新的训练样本进行模型更新,因此实现了最低的延迟。这对于需要实时预测的在线系统至关重要。
- 轻量级:Proceed 比在线集成方法 OneNet 更快、更轻量级。
3.4 表示空间可视化
为了验证“在线数据具有 OOD 概念,但概念漂移模式可能相似”的假设,作者使用 t-SNE 对历史训练数据和在线数据上的概念表示和概念漂移表示进行了可视化(如图 6 所示)。

图 6:概念表示和概念漂移表示的可视化。左图显示在线数据中存在大量 OOD 概念,而右图显示在线数据中的 OOD 概念漂移模式则少得多。
图 6a 揭示了在线数据中存在大量与历史概念不同的 OOD 概念,这解释了为何仅仅基于测试样本的概念进行适应会导致性能下降。然而,图 6b 进一步表明,在线数据中的 OOD 概念漂移模式则少得多。这一发现有力地支持了作者的直觉,即基于概念漂移进行适应比直接基于概念进行适应更具鲁棒性。
3.5 消融研究
为了深入探究 Proceed 各个组件的作用,作者进行了消融研究,引入了五个变体:
-
feedback-only:仅基于 $\mathcal{D}_{t-H}$ 的反馈进行梯度下降。
-
$\mathcal{G}\mathbf{c}_t$:仅基于测试样本的概念生成适应。
-
**$\mathcal{E}’\mathbf{X}{t-H}$**:使用相同的编码器 $\mathcal{E}’$ 从回溯窗口 $\mathbf{X}{t-H}$ 和 $\mathbf{X}t$ 中提取概念 $\mathbf{c}{t-H}$ 和 $\mathbf{c}_t$。
-
diff. $\mathbf{W}_1^{\ell}, \mathbf{W}_2^{\ell}$:生成适应系数的瓶颈层在模型层之间完全不同。
表 5:消融研究结果。我们报告了在时间范围为 {24, 48, 96} 的情况下,各个变体在每个数据集上相对于 PROCEED 模型的平均均方误差 $(MSE)$ 和相对均方误差增量 $(\bar{\Delta} MSE)$。
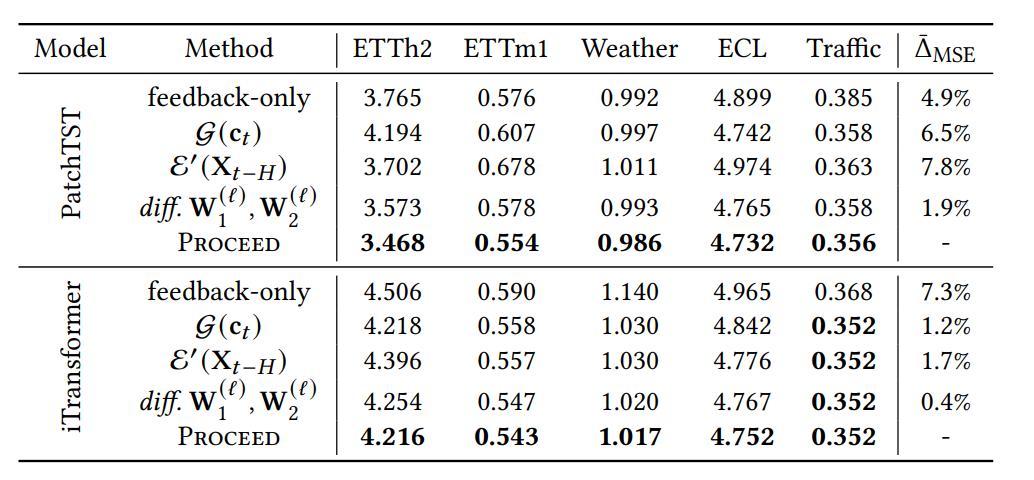
研究结果突出了主动式模型适应的关键优势。Proceed 方法显著优于朴素的 feedback-only 方法,有力地证明了主动式适应在有效缩小新训练数据与测试数据之间分布差距方面的必要性。此外,本文发现仅基于测试样本概念生成适应的变体($\mathcal{G}\mathbf{c}_t$)导致了更高的均方误差(MSE),这进一步验证了基于概念漂移进行适应的优越性,而非仅仅依赖当前概念。在编码器设计方面,使用不同编码器 $\mathcal{E}$ 和 $\mathcal{E}’$ 来提取概念比使用相同编码器效果更佳,这是因为 $\mathcal{E}$ 旨在编码最新训练样本的少量关键信息,而 $\mathcal{E}’$ 则负责编码测试样本的所有相关信息,这种分离有助于更精确地捕捉不同类型的数据特征。最后,关于模型参数化,我们观察到 Proceed 在某些层之间共享 $\mathbf{W}_1^{\ell}$ 和 $\mathbf{W}_2^{\ell}$ 的变体,其性能并未显著劣于完全不共享参数的变体。这表明在非平稳时间序列中,过度参数化的生成器可能面临更高的过拟合风险,因此适度的参数共享反而能提升模型的稳健性。
此外,作者还研究了概念编码器中对多元时间序列进行操作的不同方式,发现简单的平均操作在有效性上表现最佳。
4 结论与展望
本文深入探讨了在线时间序列预测中一个长期被忽视的关键问题:训练样本与测试样本之间固有的时间间隔所导致的概念漂移。通过详尽的实证研究,我们发现这一时间间隔严重阻碍了现有在线模型适应方法的有效性,因为它们被动地依赖于滞后的预测反馈。
Proceed 的核心思想在于其前瞻性:在对每个测试样本进行预测之前,它能够主动地适应预测模型。具体而言,Proceed 首先对最新获取的训练样本进行微调,然后利用精心设计的概念编码器从时间序列数据中提取潜在特征,以精确估计正在发生的概念漂移。随后,一个高效的适应生成器将估计出的漂移转化为精细的参数调整,这些调整是专门为当前测试样本量身定制的。为了确保框架的泛化能力,我们通过随机打乱历史数据来合成多样化的概念漂移,并在此基础上优化 Proceed,使其能够学习概念漂移与有益参数调整之间的映射关系。
在五个真实世界时间序列数据集上进行的实验证明了它显著降低了各种预测模型的预测误差,并超越了目前最先进的在线学习方法。我们的主动式模型适应方法为解决在线系统中持续的概念漂移问题提供了一个全新的方向,我们相信它将对任何存在反馈延迟的预测任务产生积极影响。
未来展望:
尽管 Proceed 取得了显著进展,但仍有许多值得深入探索的方向:
- 与持续学习的结合:Proceed 可以与现有的持续学习策略(如排练机制或正则化项)无缝结合,以进一步缓解模型在连续适应过程中可能出现的灾难性遗忘问题。
- 训练数据采样优化:Proceed 的核心思想与 SOLID 等方法中训练数据采样的概念是正交的。未来的工作可以探索将 Proceed 与更智能的训练数据采样技术相结合,以进一步提升性能。
- 伪标签生成:针对反馈延迟问题,一些同期研究提出了生成伪标签的方法。Proceed 可以探索如何利用高质量的伪标签来增强其适应能力,同时避免伪标签本身引入的潜在概念漂移。
- 更广泛的应用:Proceed 的主动适应范式不仅限于时间序列预测,有望推广到其他存在概念漂移和反馈延迟的在线预测任务中,例如在线推荐系统、欺诈检测等。

留下评论