
IDD-2504.1
DLinear&&对Transfomer以前的时间序列预测方法
到现在的所看到的论文基本都是基于transformer进行的修改,项目结构也几乎差不多。Transformer是2017年提出的,那么2017年之前的探索方向和论文成果有哪些。加上看到这个Are Transformers Effective for Time Series Forecasting?(https://arxiv.org/abs/2205.13504),我觉得有必要回顾学习以前的时间序列分析的方法来让视野更开阔。
发现两个算法收集和测试的库
TSLib提供了一个对比各种模型的统一的测试环境。
写了一个colab试着简单测试:https://colab.research.google.com/drive/1ju2e7oUW1k5ZVniHx-wLuRx9vPjAXy5C#scrollTo=g094bGQXJDO3
测试了一个最基本的ETTh1的参数:
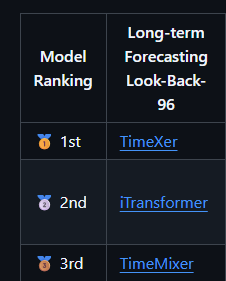
| 模型 | MAE | MSE |
|---|---|---|
| TimeXer | 0.3814 | 0.4029 |
| iTransformer | 0.3855 | 0.4046 |
| TimeMixer | 0.3748 | 0.3968 |
感觉这个就类似于LLM领域的LMarena,不过这个的评价指标是客观的,LMarena是主观的。

后续可以继续学习这里的论文和项目的构建方法。
Are Transformers Effective for Time Series Forecasting?

我第一想法这里的IMS就是transformer的自回归结构,DMS就是类似于Informer直接输出所有结果:
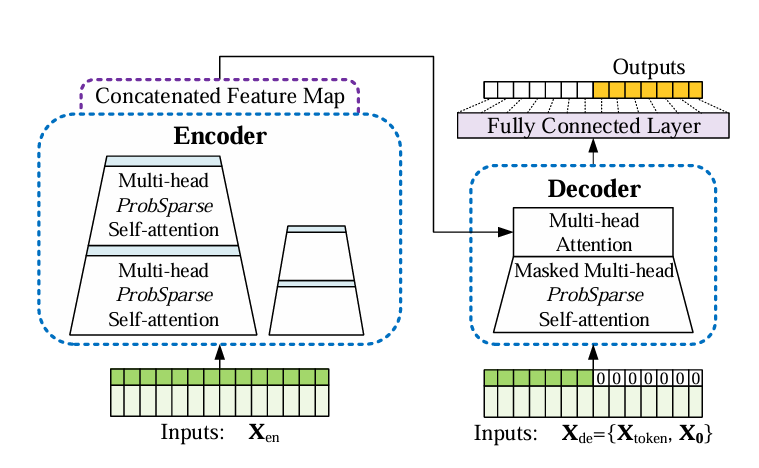
在这里作者提出基于transformer的DMS模型得到的性能提升并非由transformer所引起,下面是一个最简单的线性预测模型,结构也是DMS:
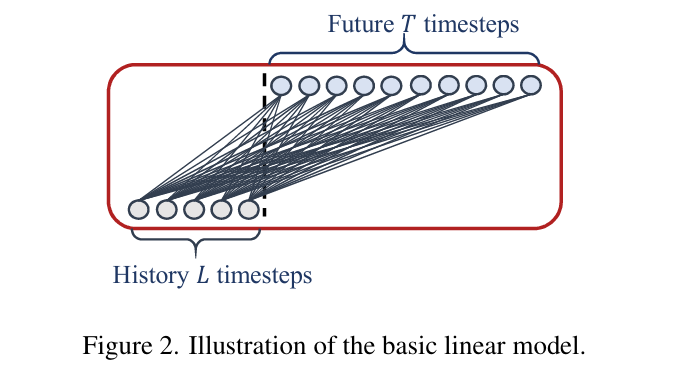
作者提出两个模型DLinear,NLinear。DLinear也在Time-Series-Library中有包括。

作者发现,线性模型击败了当时的SOTA模型FEDformer:

与开头的测试条件相同,在Colab中运行测试脚本结果对比:
| 模型 | MAE | MSE |
|---|---|---|
| TimeXer | 0.3814 | 0.4029 |
| iTransformer | 0.3855 | 0.4046 |
| TimeMixer | 0.3748 | 0.3968 |
| DLinear | 0.3961 | 0.4108 |
| FEDformer | 0.3769 | 0.4182 |
虽然不及当前的SOTA模型,于是我又对比了论文中提到的FEDformer进行测试,结果如上表所示。虽然FEDformer的结果也不算特别差,相比于DLinear在T4 GPU的执行时间只需要1分钟以内,FEDformer需要18分钟来完成这个实验。
在transformer之前有哪些时序预测方法?
这里寻找一些开创性论文,主要想了解前人是如何一步一步探索和想出这些方法的,启发是什么?
RNN(Recurrent Neural Network)
| 论文 | 链接 | 备注 |
|---|---|---|
| Learning representations by back-propagating errors(1986) | https://www.nature.com/articles/323533a0 | 提出反向传播,是所有神经网络的基础。 |
这篇文章发表于1986年的Nature上,只有短短的几页,内容就是目前的机器学习教科书。
LSTM(Long Short-Term Memory)
| 论文 | 链接 | 备注 |
|---|---|---|
| LONG SHORT-TERM MEMORY(1997) | https://www.bioinf.jku.at/publications/older/2604.pdf | LSTM的开创,引入门控机制和细胞状态解决了传统RNN在处理长序列时面临的梯度消失/爆炸问题,从而能够学习到长距离的依赖关系。 |
| Unlocking the Power of LSTM for Long Term Time Series Forecasting(2024) | https://arxiv.org/abs/2408.10006 | 最近关于LSTM的论文,Accepted by 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025) |
GRU(Gated Recurrent Unit)
| 论文 | 链接 | 备注 |
|---|---|---|
| Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation”(2014) | https://arxiv.org/abs/1406.1078 | 提出了GRU,作为LSTM的简化变体,参数更少,训练更快(EMNLP 2014) |
Seq2Seq with Attention
| 论文 | 链接 | 备注 |
|---|---|---|
| Neural Machine Translation by Jointly Learning to Align and Translate(2014) | https://arxiv.org/abs/1409.0473 | 将注意力机制引入Seq2Seq模型(ICLR 2015) |
直到2017年Attention Is All You Need开启了Transformer的时代,出现了许多的变体。后期继续学习这些2017年之前的实际序列预测方法。
学习项目/模型结构
目标
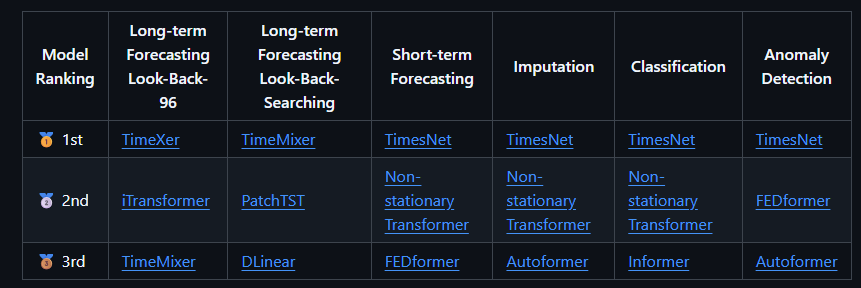
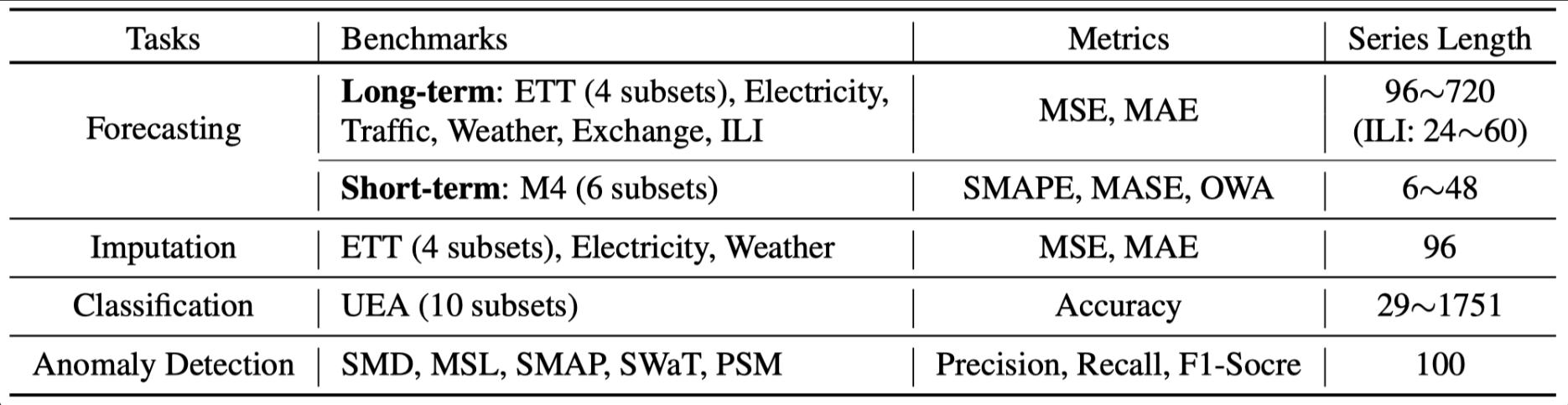
这6个任务分别是:长期预测:回看窗口96、长期预测:回看窗口搜索、短期预测、插补/补全、分类、异常检测。
具体的测试条件:
DLinear:
class Model(nn.Module):
def __init__(self, configs, individual=False):
def encoder(self, x):
def forecast(self, x_enc):
def imputation(self, x_enc):
def anomaly_detection(self, x_enc):
def classification(self, x_enc):
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec, mask=None):
-
__init__: 构造函数,用于初始化模型的参数和组件。根据任务类型(如分类、异常检测、插值等)设置预测长度,并初始化线性层(Linear_Seasonal和Linear_Trend)用于时间序列的分解和预测。 -
encoder: 编码器函数,接收输入数据x,通过时间序列分解模块(series_decomp)将输入分解为季节性成分和趋势成分,然后通过线性层对这些成分进行处理,最后将它们合并为编码输出。 -
forecast: 用于时间序列预测任务,调用encoder对输入数据进行编码并返回预测结果。 -
imputation: 用于时间序列插值任务,调用encoder对输入数据进行编码并返回插值结果。 -
anomaly_detection: 用于异常检测任务,调用encoder对输入数据进行编码并返回检测结果。 -
classification: 用于分类任务,调用encoder对输入数据进行编码,然后通过一个全连接层(projection)将编码结果映射到分类结果。 -
forward: 模型的前向传播函数,根据任务类型调用相应的功能函数,并返回对应的输出结果。在NPU上运行torch:更新
在上周讲到要写三行代码:
import torch_npu from torch_npu.npu import amp # 混合精度支持 from torch_npu.contrib import transfer_to_npu # 自动迁移工具在看到modelarts里的教程(3)发现他们使用NPU并没有导入torch_npu,只导入了torch:
 于是我测试只使用一行代码:
于是我测试只使用一行代码:from torch_npu.contrib import transfer_to_npu # 自动迁移工具添加在import torch的位置即可,效果是一样的。
疑惑?
1.一个模型为何能应用到不同的任务之中?
2.为什么IMS自回归结构比DMS多了许多算力却结果会更差?
3.为什么现在的论文基本都根据transformer架构进行改进?
下一步计划
1.学习模型的构建方法,学习根据方案理解并动手实现一个模型的思路
2.学习neuralforecast项目

留下评论