
Idd 2505.1
合成时间序列数据方法 && S2微分方程形式
1.Chronos
Chronos 核心概念:
1.将时间序列视为”语言”进行建模
2.通过缩放和量化将时间序列转换为离散 token
3.利用现有语言模型架构进行时间序列预测
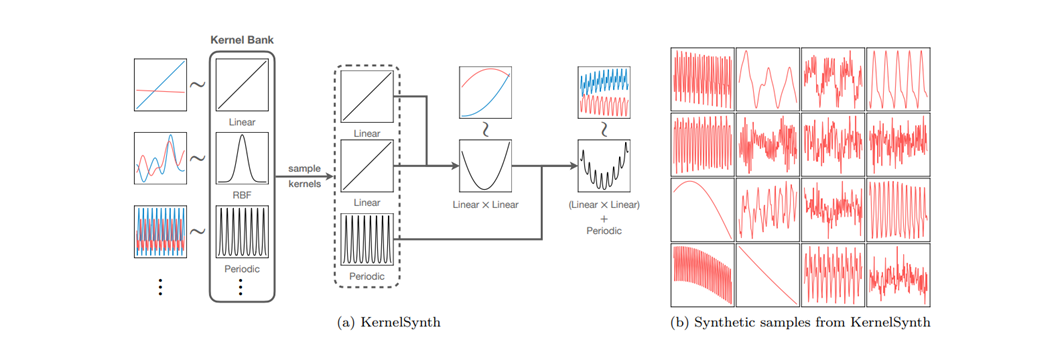
上图为Chronos的序列生成方法。
Chronos 的预训练数据由两个主要部分组成:
1.真实公开数据集
•采集了大量真实世界的公开时间序列数据集,涵盖多个领域(如零售、能源、金融、医疗、气候等),用于增强模型对不同领域的泛化能力。
2.合成数据
•使用高斯过程(Gaussian Processes)自动生成的时间序列,用来弥补真实数据的稀缺性和多样性不足。
•合成过程采用一种称为 KernelSynth 的技术,通过随机组合核函数生成多样的时间序列模式。
KernelSynth算法:

算法简单解释:
算法涉及三个主要的部分:核函数 (Kernel)、组合操作 (+, ×)、高斯过程 (GP) 。
输入:1.核函数库 K 2.每条时间序列的最大核函数数量 3.时间序列长度
输出:1.一条合成的时间序列
之后随机选择模式数量、随机选择基础模式、随机选择模式参数、随机组合模式、高斯过程采样。
1.$j ~ U{1, J}$:从1~J之间随机选一个整数 j
2.${κ_1(t,t’), …, κ_j(t,t’)} ~ i.i.d K$:从核函数库 $K$中,独立、随机地挑选 $j$ 个核函数
3.$κ* ← κ_1$:先把第一个选中的核函数 $κ_1$ 作为初始的组合核 $κ*$
4.⋆ ~ {+, ×}:随机选择一个操作符:加法或乘法 (×)
5.$κ* ← κ* ⋆ κ_i$:当前的组合核 $κ$ 和新的核 $κ_i$进行运算,更新 $κ$
6.$x_1:l_{syn}$~ $GP(0, κ*(t, t’))$:从一个高斯过程 (GP)中进行采样,得到最终的时间序列
2.TIME-MOE
| 领域 | 占比(按观测点数量) | 数据说明 |
|---|---|---|
| Nature(自然类) | 90.50% | 最大的子集,如气温、降水、气象等 |
| Synthetic(合成) | 2.98% | 用于增强数据的多样性 |
| Energy | 5.17% | 能源消耗、电力负载等 |
| Transport | 0.69% | 如交通流量等 |
| Web | 0.58% | 网络数据,如访问流量、用户行为等 |
| Finance | 极少(~0.0001%) | 金融市场的时间序列 |
| Healthcare | 极少(~0.0001%) | 医疗健康相关时间序列 |
| Sales | 0.008% | 零售销售数据 |
| Other | 0.006% | 其他类别 |
在世界上有许多的气象站,这些数据也非常适合作为预训练数据,因为和合成的数据一样有着复杂的动力学基础。
3.Panda
数据生成示意图:
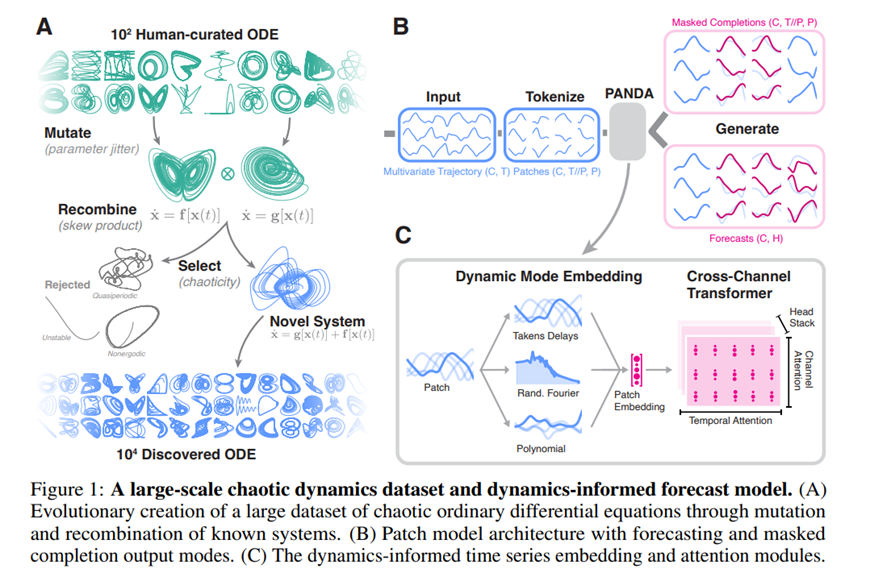
Panda的数据生成基于混沌系统:
-
起点 (10² Human-curated ODE): 过程始于100个(10的2次方)由人类发现和整理的已知混沌系统。这些系统由常微分方程(ODE)描述。
-
变异 (Mutate): 随机选择一个系统,并对其控制参数进行微小的扰动。就像生物进化中的基因突变,可能会产生一个行为略有不同的新系统。
-
重组 (Recombine): 随机选择两个系统,将它们的方程(
ẋ = f[x(t)]和ẋ = g[x(t)])通过一种叫做“斜积”(skew product)的方法组合起来,形成一个更复杂的新系统。 - 选择 (Select): 新生成的系统并非都有用。研究者会对其进行筛选,标准是混沌性 (chaoticity) 。
- 保留 (Novel System): 只有那些表现出混沌特性的新系统才会被保留下来,成为“新发现的系统”。
- 拒绝 (Rejected): 如果新系统是不稳定的(轨迹发散到无穷大)、准周期的(Quasiperiodic,行为有规律但不是严格重复)或非遍历的(Nonergodic,轨迹无法探索整个吸引子),它们就会被丢弃。
- 终点 (10⁴ Discovered ODE): 通过不断重复“变异、重组、选择”这个进化过程,研究者们最终从最初的100个系统扩展到了10,000个(10的4次方)全新的、经过验证的混沌系统。这为训练和测试模型提供了海量且多样化的数据。
4.Timer的训练数据
Timer的训练数据是非合成的。
5.MOIRAI
MOIRAI使用作者收集的LOTSA数据集
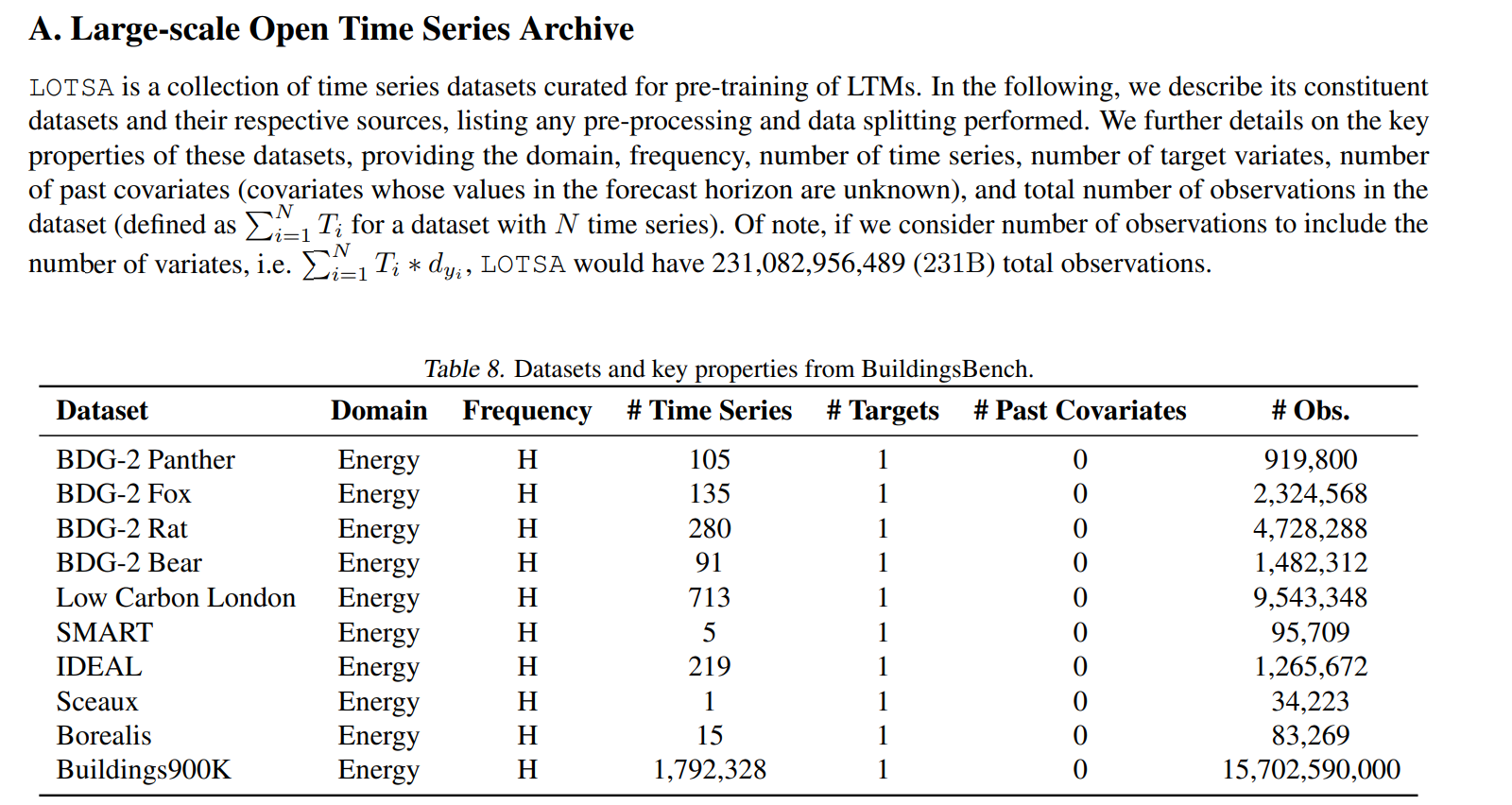
除了能源还有别的9个领域
6.forecastFPN
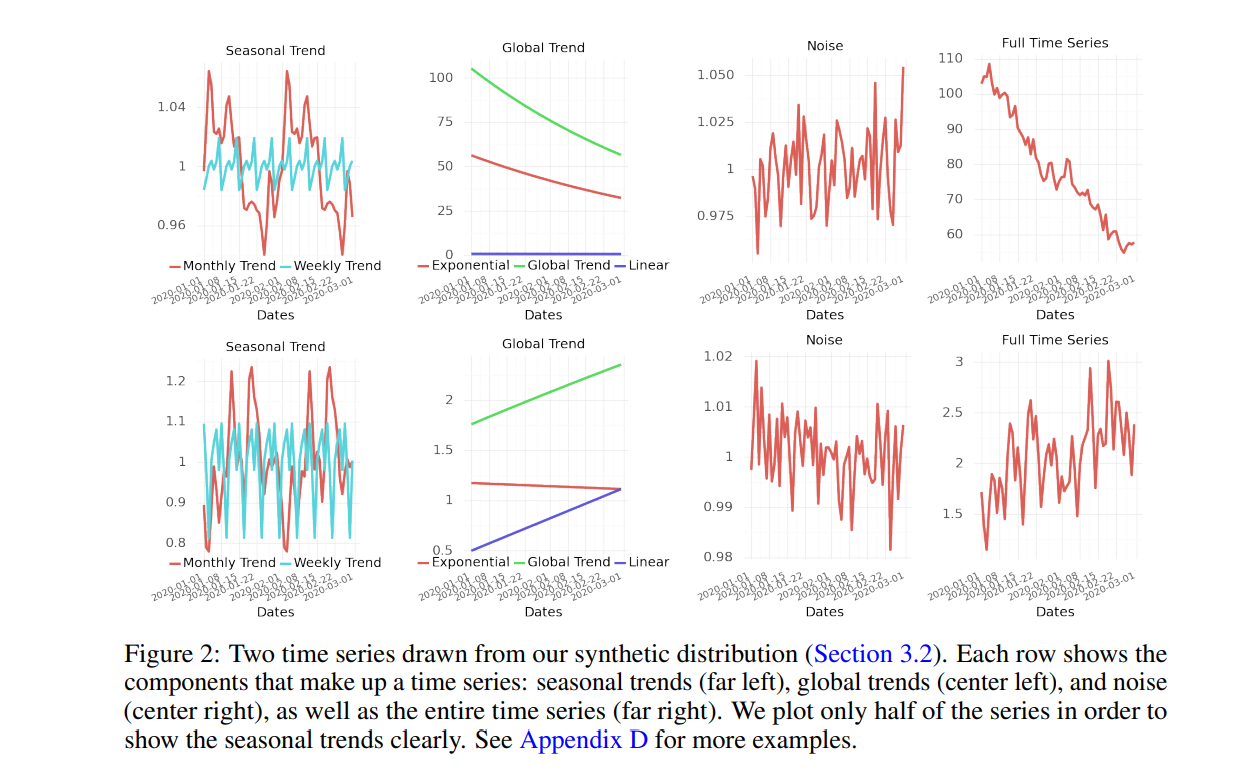
合成数据基于一个核心假设,即时间序列由两个独立部分组成:基础序列(Base Series)和噪声(Noise)。
生成基础序列包括趋势(Trend)成分和季节性(Seasonal)成分,具体的公式如下:

S2dataset进度
目前的方法为 $y=f(x)$
目标:要改成$\dot{y}=f(x)$对应的$y=f(x)$的函数的时间序列
方法采用梯形积分法,通过对函数每0.001的点进行采样获得函数值,再对函数值从0到$i$通过梯形积分法做定积分。
效果图,这里选取一个简单的甚至可以手算验证x=2左右的点:
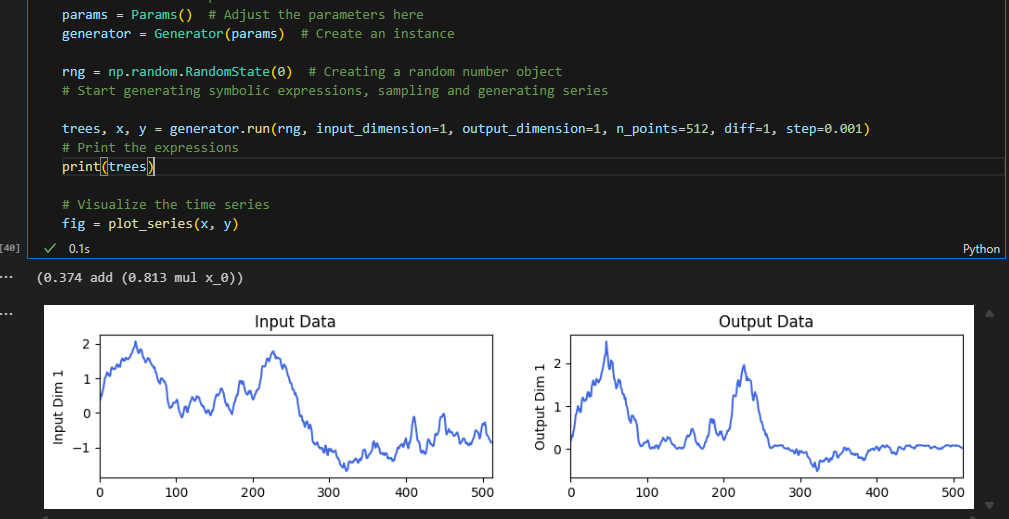
目前提交了pr并且合并了到了原代码仓库。

留下评论