
IDD-2504.2
华为云NPU的使用方法&&多卡测试
1.额度转代金券
登录帐号以后点击链接:https://developer.huawei.com/home/center/incentive/my-quota
账号ID查询方式,在需要代金券的账号悬浮在华为ID上获得华为账号ID,具体参考微信里的资料。
2.1配置环境(1)模型训练入口(暂时无法启动CUDA,方法(2)可用)
经过测试,使用预置框架没法调整启动参数,必须要做一个镜像来启动。
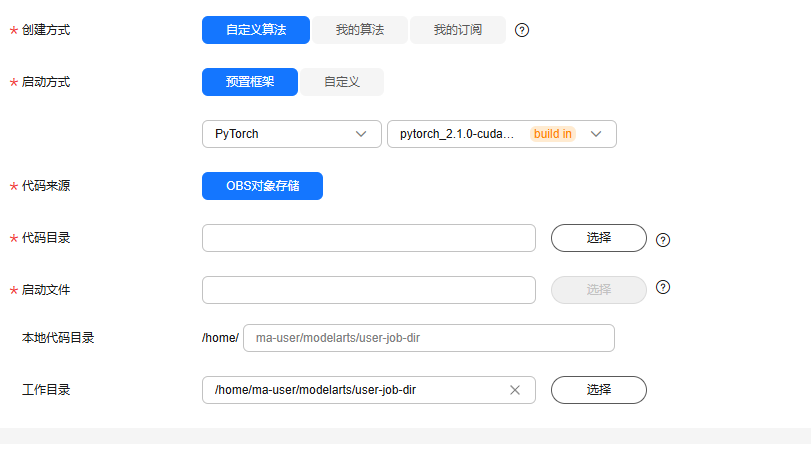
最简单的方法是使用上方的notebook:

选择需要的基础预置框架:
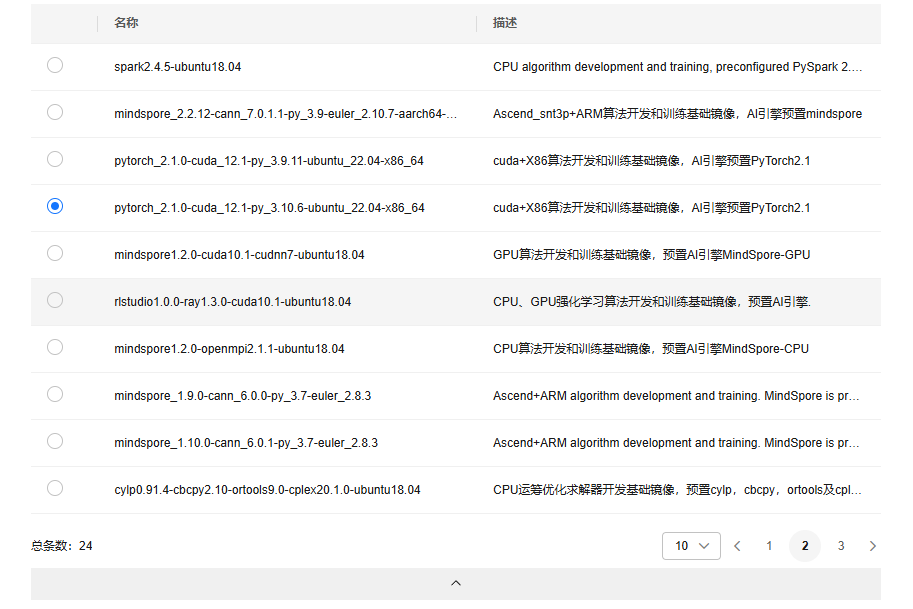
这里直接用cpu启动,把requirements.txt拖到左侧的文件栏,启动终端
pip install -r requirements.txt
安装完成之后即可返回notebook主页点击保存当前的框架,这里跟着步骤走即可。
保存需要一定的时间大概10分钟,再次打开模型训练的训练作业,即可看到刚刚保存好的环境:
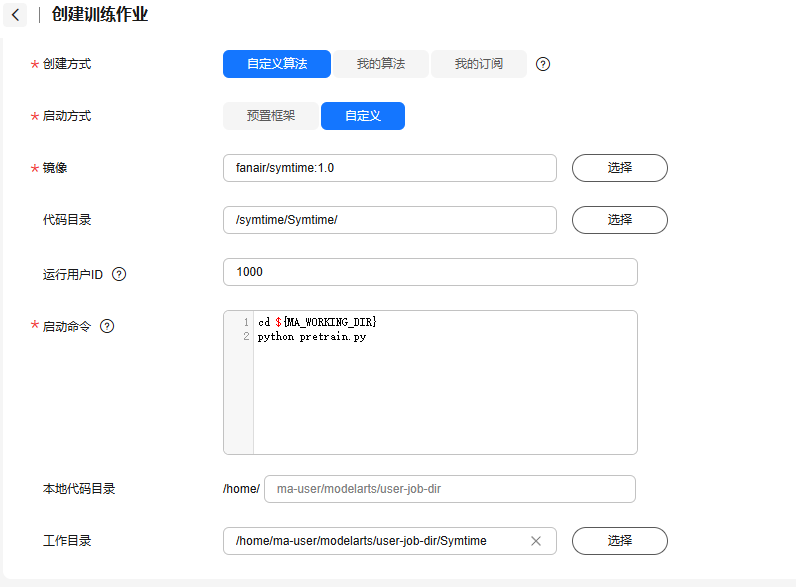
cd ${MA_WORKING_DIR}
python pretrain.py
2.2配置环境(2) Notebook入口(NPU最大64GB*8显存)
Notebook其实也和上面的(1)存在同样的问题,于是转向NPU来尝试,在这里发现https://developer.huaweicloud.com/develop/aigallery/article/detail?id=7860d972-247f-4d4a-af65-7f0f22b678c5有torch==2.1.0配NPU的镜像,所以需要把位置切换到华东二,华东二只提供Ascend NPU。
该配置方法比(1)更简单,因为就和普通notebook一样,不过需要通过OBS存储桶传递100MB以上的文件。
1.配置原始镜像
注册镜像
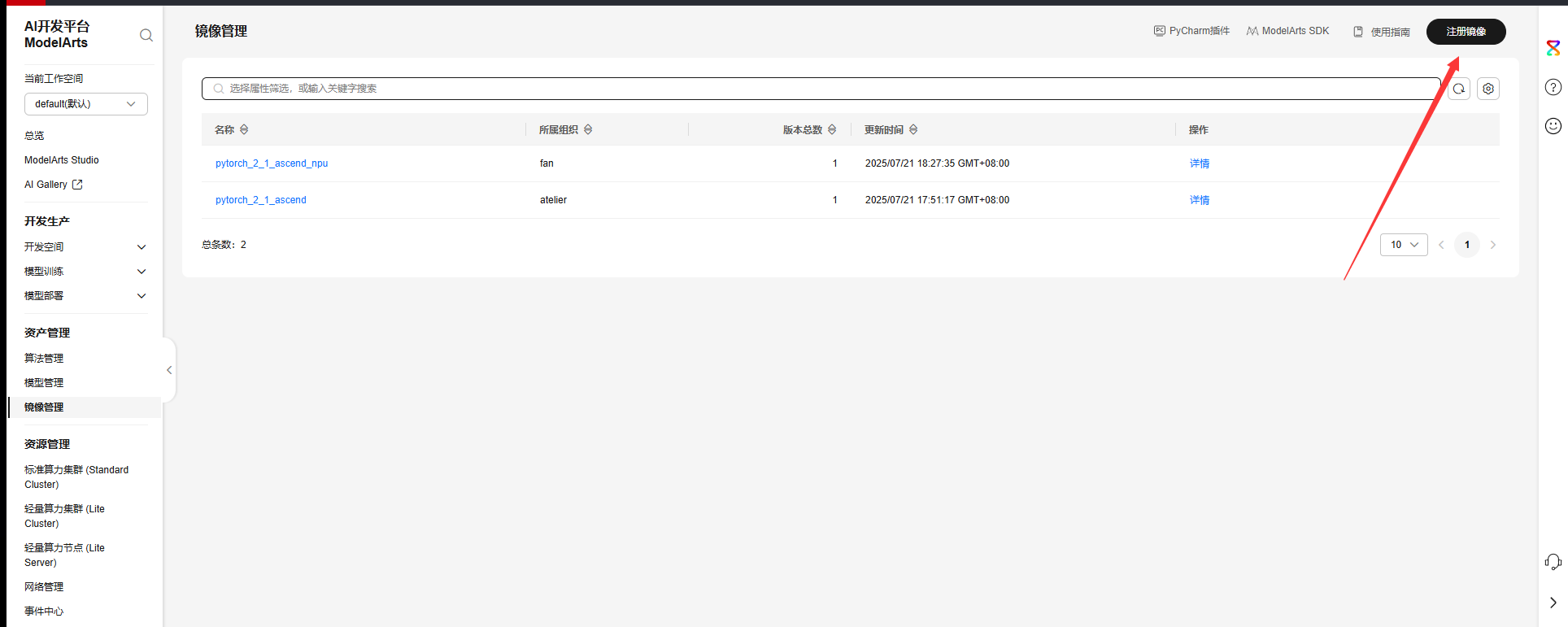
配置好之后注册,就会在列表中出现该镜像:
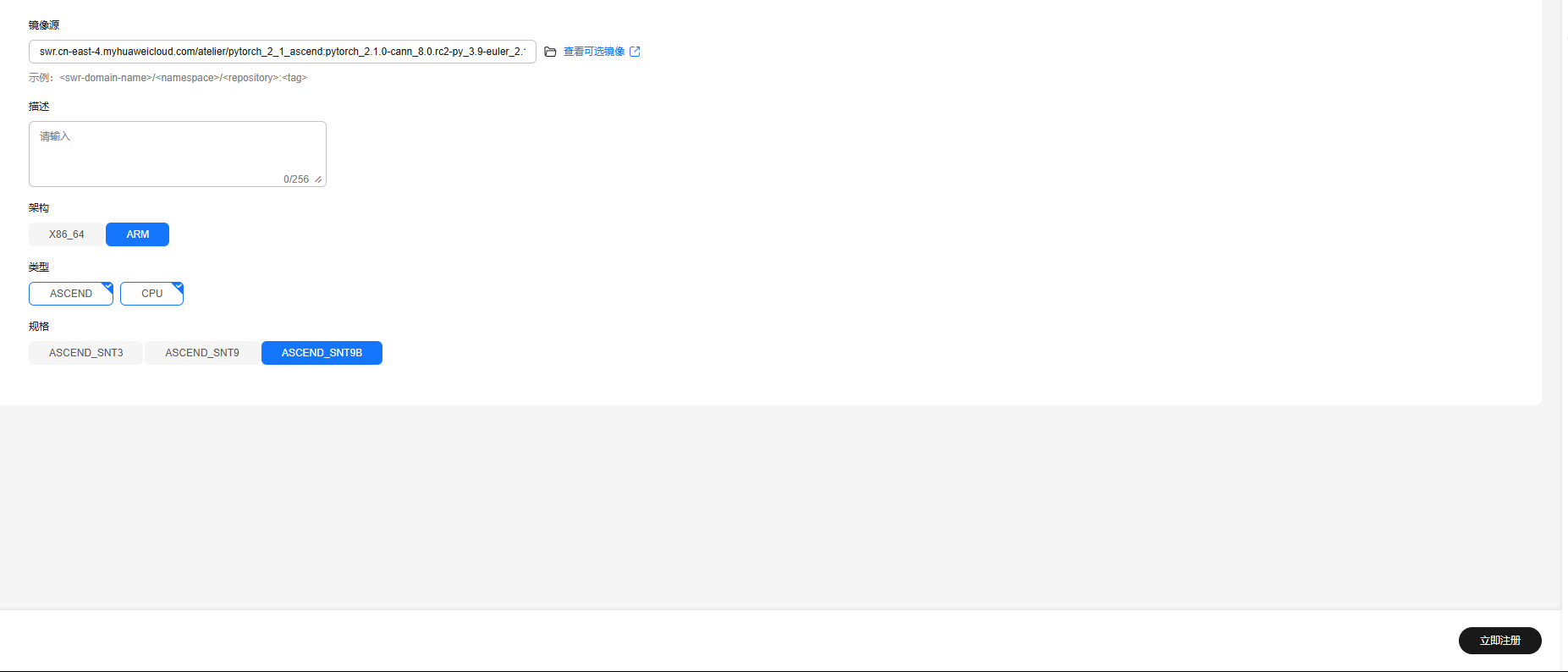
在创建notebook里选择该镜像,这里图片是我配置好环境保存的新镜像。
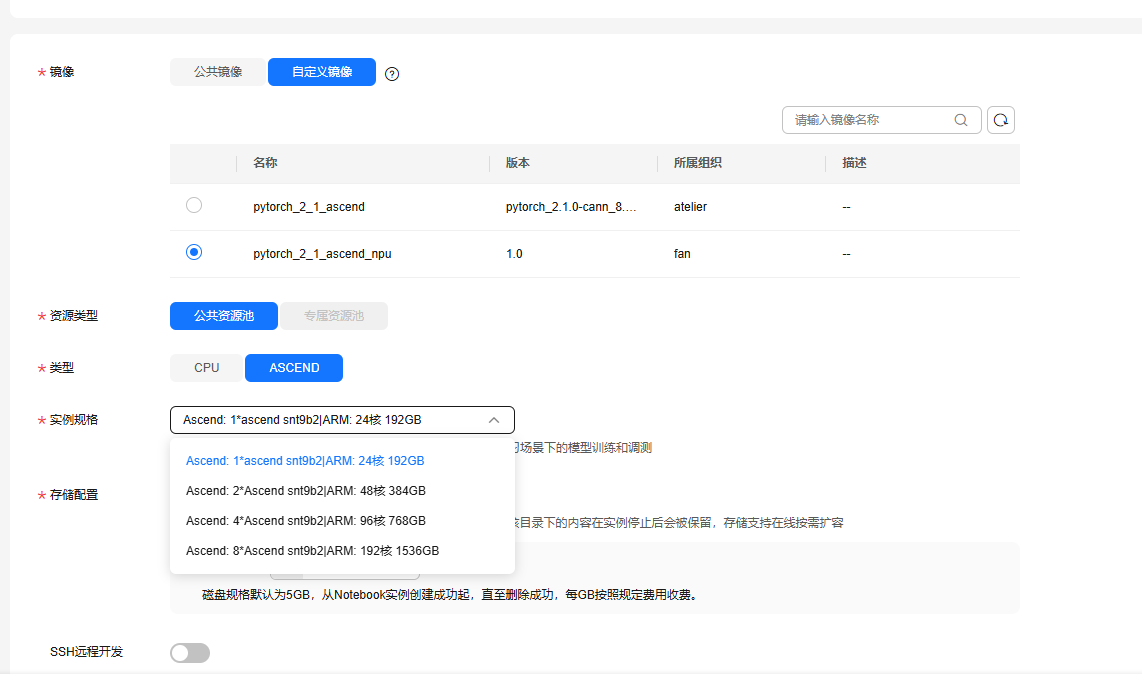
3.配置存储桶
搜索OBS对象存储服务
创建一个桶,然后把需要运行的文件存在这里即可。
由于每次限制上传100个文件,Symtime有500个文件左右,所以需要下载OBS Browser+:https://support.huaweicloud.com/browsertg-obs/obs_03_1003.html
根据https://support.huaweicloud.com/usermanual-ca/ca_01_0003.html教程获取登录密钥。
使用AK方式登录即可。
一次上传最大500个文件。这里配置好的文件地址会在创建训练目录时选择:

4.1 启动运行训练模型
这里启动命令经过测试使用绝对地址会报错,所以直接用最简单的相对地址。
在model_interface.py里,不知道因为什么原因,这里的self.model_type会变成一串绝对地址出现报错No such file or directory,需要对文件修改:
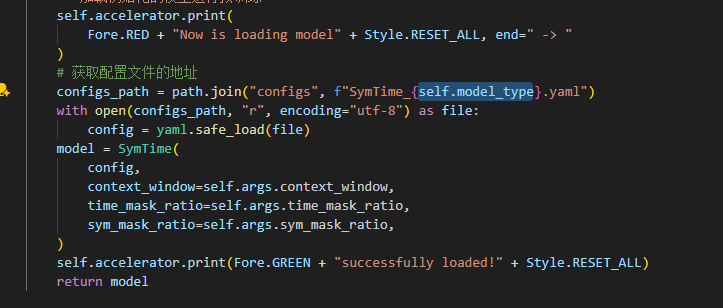
修改这个变量为字符串和文件里的Symtime_base.yaml对应即可正常运行。
正常能跑的情况下出现一个没遇到过的警告问题:
DistilBertSdpaAttention is used but torch.nn.functional.scaled_dot_product_attention does not support output_attentions=True or head_mask. Falling back to the manual attention implementation, but specifying the manual implementation will be required from Transformers version v5.0.0 onwards. This warning can be removed using the argument attn_implementation="eager" when loading the model.
4.启动运行Notebook
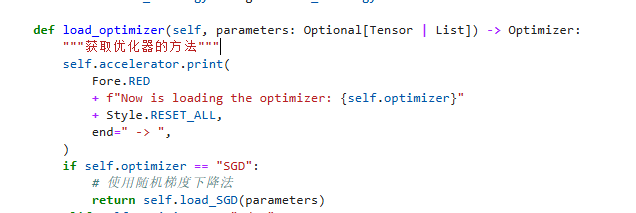
由于内置的镜像为Python3.9所以要把这行改成:
def load_optimizer(self, parameters: Optional[Union[Tensor, List]]) -> Optimizer:
在导入部分:
from typing import Optional, List, Union
如果加载好的是配置好的镜像,假设你的文件名是Symtime-NPU,那么:
unzip Symtime-NPU
cd Symtime-NPU
python pretrain.py
如果是从新镜像开始那么先配置pip。
5.监控
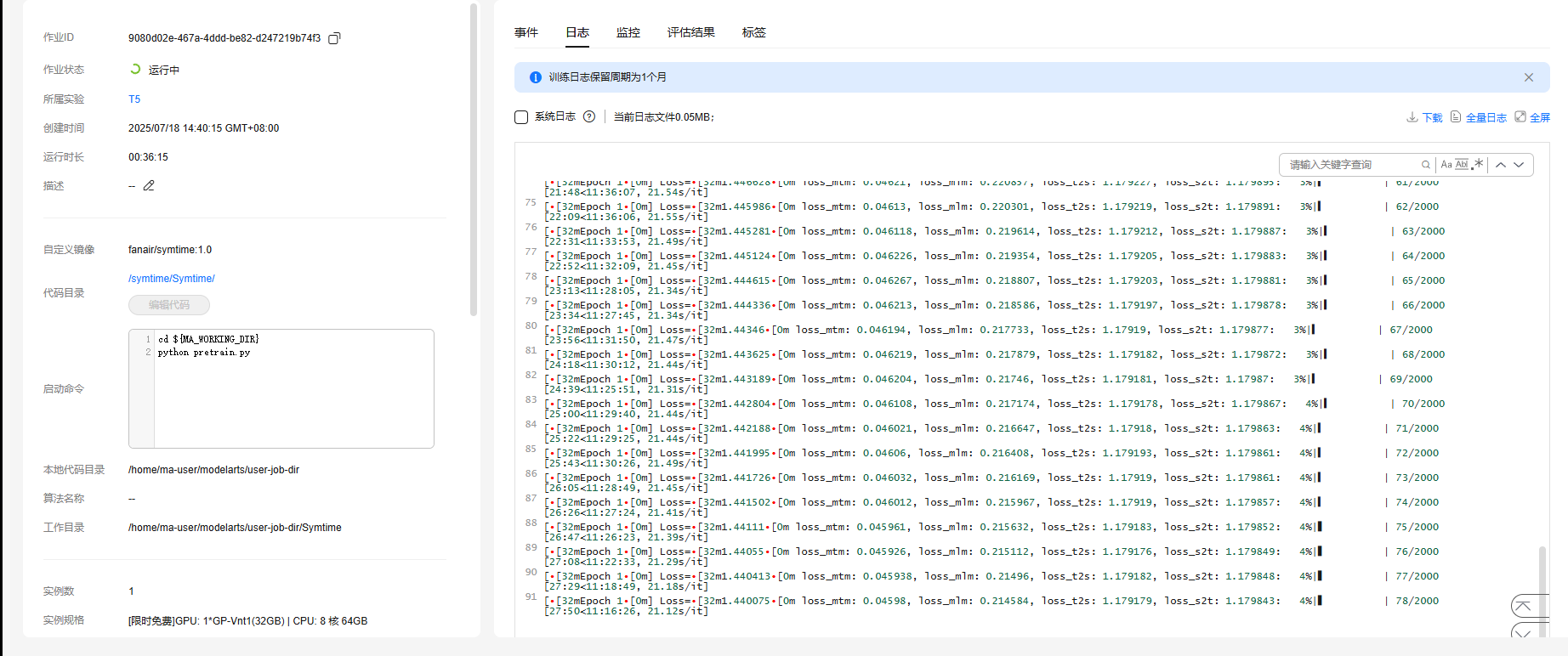
将这里的系统日志取消勾选,看到的就是一般的训练日志。
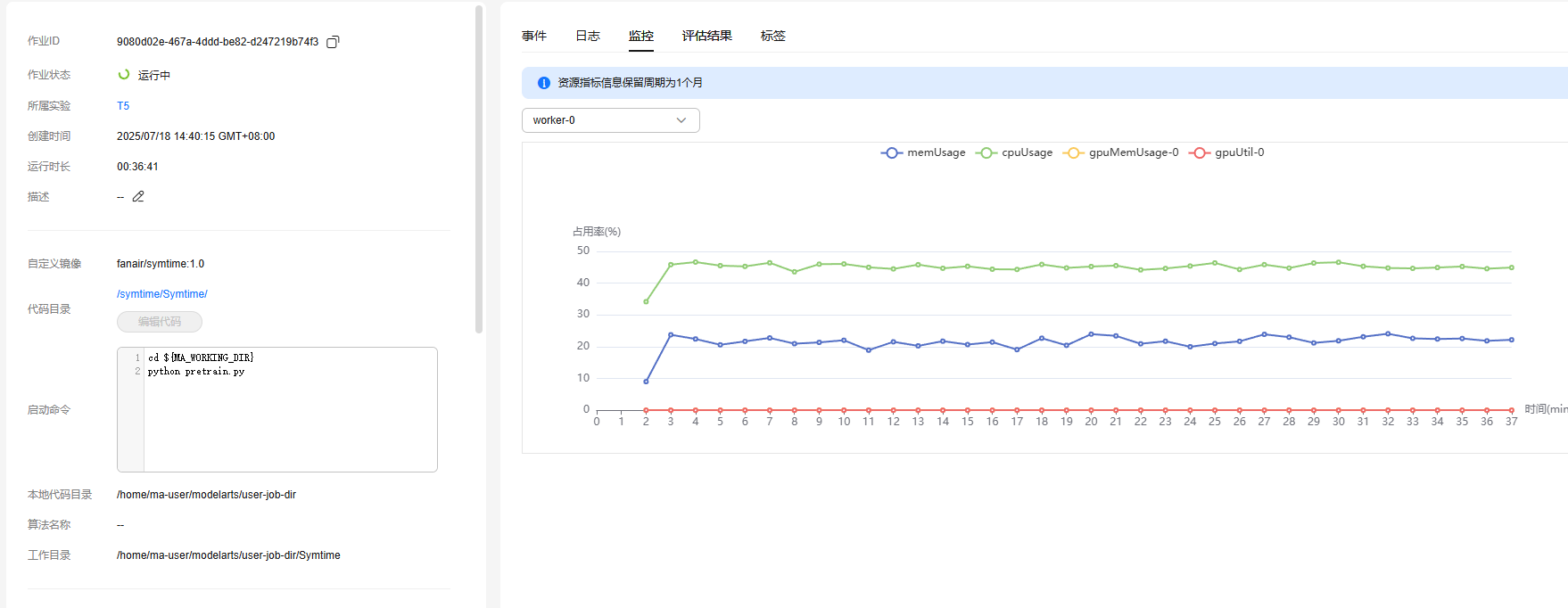
监控界面不知道为什么GPU占用始终为0,难道说没有启用GPU?但是训练程序运行没有其他异常。
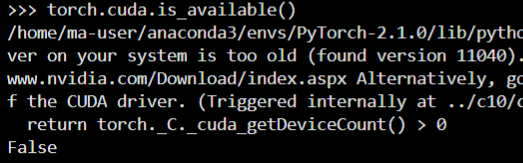
经过测试发现,华为虽然标的是cu12.1,但是在环境里的镜像是cuda11.4,这导致没有启动GPU:
5.1 监控notebook
右边是使用率,其他就是一个linux虚拟机。
由于没有跑满内存,所以继续尝试了:
python pretrain.py --batch_size 32
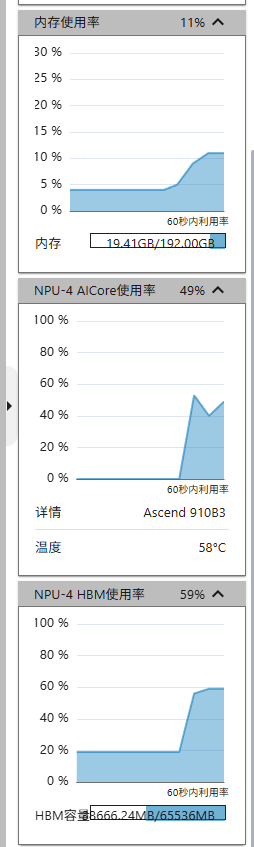
提高了batch_size之后占用率可以拉上来了。
多卡测试
官方链接:https://www.hiascend.com/document/detail/zh/Pytorch/60RC2/ptmoddevg/trainingmigrguide/PT_LMTMOG_0084.html?sub_id=%2Fzh%2FPytorch%2F60RC2%2Fptmoddevg%2Ftrainingmigrguide%2FPT_LMTMOG_0080.html
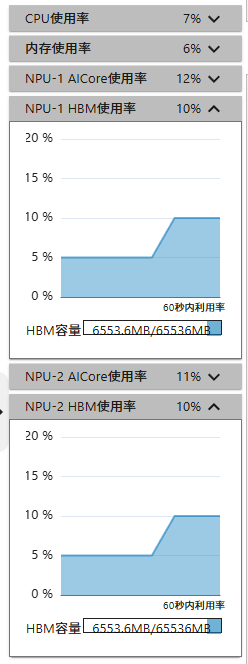
跟着官方demo走了一遍,发现HBM没有变化,于是调整了网络参数:
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 8192),
nn.ReLU(),
nn.Linear(8192, 8192),
nn.ReLU(),
nn.Linear(8192, 10)
)
终于可以看到调用NPU的效果:
基本概念:
| 概念 | 说明 |
|---|---|
| world_size | 总进程数 = 总设备数(如8卡就是8) |
| rank | 当前进程的唯一编号(0~world_size-1) |
| local_rank | 当前进程在当前机器上的编号(0~设备数-1) |
| backend | 通信后端,如hccl(华为 NPU 特有) |
| init_method/env | 初始化进程组所使用的方式,env://最常见 |
适配Symtime的DDP
原始代码采用accelerate对GPU设备进行管理,而在华为的官方的手册里,需要采用DDP的方式来指定model的device。
经过测试,使用自动迁移不会启用多卡,所以这里需要手动迁移。
model = DDP(model, device_ids=[local_rank_idx])
难点在于如何迁移acclerate并实现和单卡一致的效果。
原始代码通过accelerate实现设备自动管理:
self.accelerator.print(
Fore.RED + "Now is loading pretraining data" + Style.RESET_ALL,
end=" -> ",
)
train_loader = self.data_interface.get_dataloader()
train_loader = self.accelerator.prepare_data_loader(
train_loader, device_placement=True
)
sleep(2)
self.accelerator.print(
Fore.GREEN + "successfully loaded!" + Style.RESET_ALL
)
self.model.train()
data_loader = tqdm(train_loader, file=sys.stdout)
for step, (time, time_mask, sym_ids, sym_mask) in enumerate(
data_loader, 1
):
self.optimizer.zero_grad()
num_samples += time.shape[0]
# 直接在模型正向传播的过程中获得损失
loss_mtm, loss_mlm, loss_t2s, loss_s2t = self.model(
time, time_mask, sym_ids, sym_mask
)
# 获取和整合误差
loss = loss_mtm + loss_mlm + (loss_t2s + loss_s2t) / 2
# 误差的反向传播
self.accelerator.backward(loss)
如何把acclerate迁移到华为官方的DDP?
官方实现:
def train(args):
"""训练函数"""
world_size = int(os.environ["WORLD_SIZE"]) # 获取分布式训练的进程数
local_rank_idx = int(os.environ["LOCAL_RANK"]) # 获取本地进程索引
devices_per_node = torch.npu.device_count() # 获取每个节点的 NPU 设备数量
dist.init_process_group("hccl", rank=local_rank_idx, world_size=world_size, timeout=timedelta(minutes=30)) # 初始化分布式进程组
torch_npu.npu.set_device(local_rank_idx) # 设置当前使用的 NPU 设备
device_id = f"npu:{local_rank_idx}" # NPU 设备标识
model = ToyModel().to(device_id) # 实例化模型并移动到指定设备
model = DDP(model) # 包装模型以支持分布式训练
官方启动脚本:
#!/bin/bash
# 设置环境变量
export MASTER_ADDR="localhost"
export MASTER_PORT="12345"
export WORLD_SIZE=8 # 总的NPU数量
# 启动多个进程
for ((local_rank=0; local_rank<$WORLD_SIZE; local_rank++))
do
export LOCAL_RANK=$local_rank
python train_8p_shell.py &
done
wait
这里的需要注意的是,在Notebook里的并不是运行时的local_rank=1,而应该依然是local_rank=0,Notebook里监控的启动每次的起始序号不需要管它。
由于不是很熟悉这两个方法,让Claude写了根据参考资料个写了个demo脚本,虽然能运行,但是NPU的占用率起不来,查看了翻译的代码,有些逻辑和原始的对不上,存在和原始的文件对齐的问题还需要进一步修改。
总结
1.目前在学习accelerate和DDP之间的适配NPU问题。
2.虽然目前有个简单的demo可以运行,但是效率还需要改进。
3.根据文档学习还有没有别的方法更好的方法实现多卡。

留下评论