
Idd 2505.0
预训练时序模型和合成数据集
研究Synthetic Series-Symbol Data Generation for Time Series Foundation Models
合成数据集:1.合成输入数据
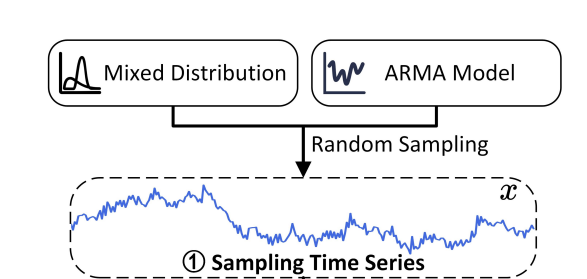
问题1:这里的Mixed Distribution和ARMA Model是什么?
答:①mixed distribution 指的是一种由多个概率分布组合而成的数据生成方式。
②ARMA 是时间序列建模中非常经典的一个统计模型,由两个部分组成:
- AR(Auto Regressive)自回归部分:当前值由过去几个时间点的值线性决定。
- MA(Moving Average)滑动平均部分:当前值也受到过去噪声项的影响。
公式:
\[Y_t = \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \cdots + \phi_p Y_{t-p} + e_t - \theta_1 e_{t-1} - \theta_2 e_{t-2} - \cdots - \theta_q e_{t-q}\]$\phi_p$ 和 $\theta_q$ 是MA和AR过程的参数。 $e_t \sim \mathcal{N}(0, 1)$是白噪音项.
问题2:为什么要有白噪音项?
答:残差序列概念: “真实值” 与 “模型预测值” 之间的差值所组成的序列
1.白噪音是时间序列模型之所以是“随机过程”模型而不是“确定性”模型的原因。它是驱动整个序列不断变化的引擎。
2.白噪音代表了模型的预测误差,是模型解释能力的边界。一个好的ARMA模型,其残差序列应该表现为白噪音。
问题3:具体的合成过程是什么?
答:
- 以不大于 $0.5$ 的概率 $P$,序列从一个由 $k$ 个分布构成的混合体中抽取,$k$ 值服从 $\mathcal{U}(1, k_{\max})$ 均匀分布。在此混合体中:
- 各分量的权重 $w_j$ 从 $\mathcal{U}(0,1)$ 均匀分布中独立抽取并归一化,使其总和为 $1$。
- 每个分量本身是:一个正态分布 $\mathcal{N}(\mu_j, \sigma_j^2)$(其中 $\mu_j \sim \mathcal{N}(0,1)$,$\sigma_j \sim \mathcal{U}(0,1)$),或者一个从 $\mathcal{U}(0, \mu_j)$ 中抽取的均匀分布。
- 否则(即以 $1-P$ 的概率),序列从一个 ARMA$(p, q)$ 过程中生成,其中:
- 自回归阶数 $p$ 服从 $\mathcal{U}(1, p_{\max})$ 均匀分布。
- 移动平均阶数 $q$ 服从 $\mathcal{U}(1, q_{\max})$ 均匀分布。
- 模型参数 $\phi_i$ 和 $\theta_j$ 从 $\mathcal{U}(-1, 1)$ 均匀分布中抽取。
-
通过满足条件 $\sum_i \phi_i < 1$ 和 $ \phi_p < 1$ 来确保过程的平稳性。
构造f(x)输出数据
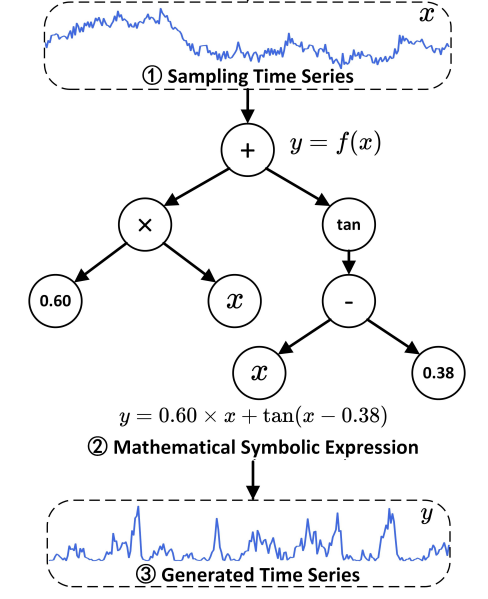
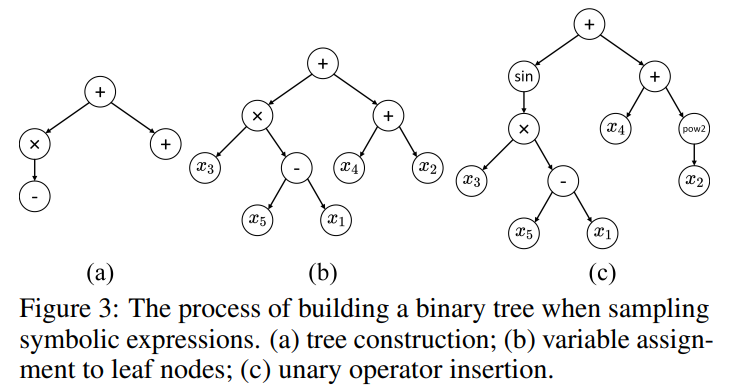
这个过程还是非常清晰的。
模型架构
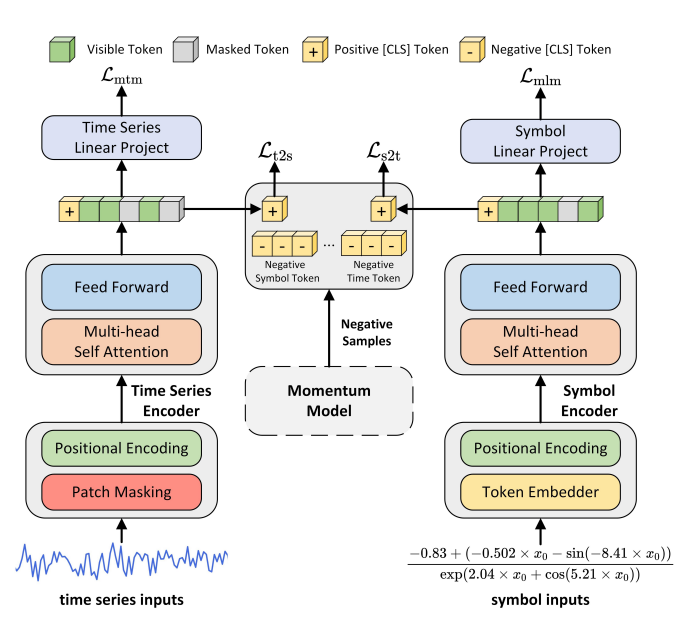
问题4:[CLS] token是什么?
答:[CLS] 是 “classification” 的缩写,是 Transformer 模型(特别是 BERT 及其衍生模型)中专门加在输入序列最前面的一个 特殊 token。
问题5:momentum encoders是什么?
答:He:https://arxiv.org/abs/1911.05722
作为对比学习部分,生成符号和序列的关系。
MOCO:
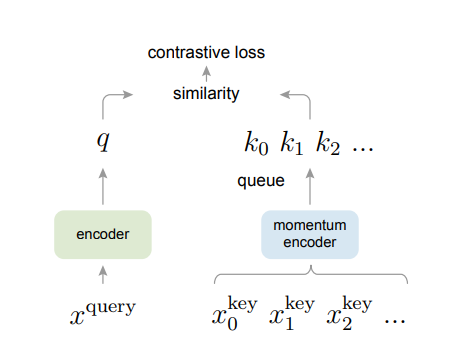
对应于原文:
序列-符号对比学习。 为了利用强相关性的系列-符号数据对,我们采用对比学习,使用符号信息增强时间序列表示。使用动量编码器,我们通过线性投影 $g_t, g_s$ 投影 [CLS] 嵌入,并定义 $\text{sim}(t, s) = g_t(t_{\text{cls}})^{\top} g_s’(s_{\text{cls}}’)$,其中 $g_s’(s_{\text{cls}}’)$ 是由动量模型生成的归一化符号特征。类似地,$\text{sim}(s, t) = g_s(s_{\text{cls}})^{\top} g_t’(t_{\text{cls}}’)$。我们计算: $p^{t2s}(t) = \frac{\exp(\text{sim}(t, s_m)/\tau)}{\sum_m \exp(\text{sim}(t, s_m)/\tau)}, p^{s2t}(s) = \frac{\exp(\text{sim}(s, t_m)/\tau)}{\sum_m \exp(\text{sim}(s, t_m)/\tau)}$,其中 $\tau$ 是一个可学习的温度参数。令 $y^{t2s}(t)$ 和 $y^{s2t}(s)$ 表示独热相似度,正样本对的概率为1,负样本对的概率为0。我们优化 $\mathcal{L}_{\text{tsc}} = \frac{1}{2} \mathbb{E}[H(y^{t2s}, p^{t2s}) + H(y^{s2t}, p^{s2t})]. \quad$
问题6:什么是patch Masking?为什么要把数据遮住一部分?
答:实现模型的自监督训练,让模型学到上下文的关系。
图:MLM

问题7:什么是动量蒸馏 (Momentum Distillation)?
https://arxiv.org/abs/2107.07651
S2数据集生成研究
这两天没搞懂需求写了一个版本,相当于白干了一天多,但是看明白了大部分结构。
目前已经看懂基本的结构,下一步的计划是从$y=f(x)$改成$y’=f(x)$的时间序列生成方法。
下一步的计划
1.还有一些基础模型的论文要看:
| 论文 | 链接 |
|---|---|
| Time-MoE | https://arxiv.org/abs/2409.16040 |
| MOIRAI | http://arxiv.org/abs/2402.02592 |
| Timer | https://arxiv.org/abs/2402.02368 |
| Chronos | https://arxiv.org/abs/2403.07815 |
2.大部分时间研究S2数据生成并实现微分方程的时间序列。

留下评论