
Week 3
把模型跑在NPU上&&torch-npu&&Huawei Mindspore
将一个基于Pytorch的项目跑在华为ASCEND NPU上有两种方法:
1.直接安装华为NPU的Pytorch支持库:
import torch_npu
from torch_npu.npu import amp # 混合精度支持
这些库在华为的Notebook里都已经安装好了。
接着是进行模型迁移:
from torch_npu.contrib import transfer_to_npu # 自动迁移工具
导入自动迁移工具。
这里先使用的是Informer的Notebook来进行初步测试:
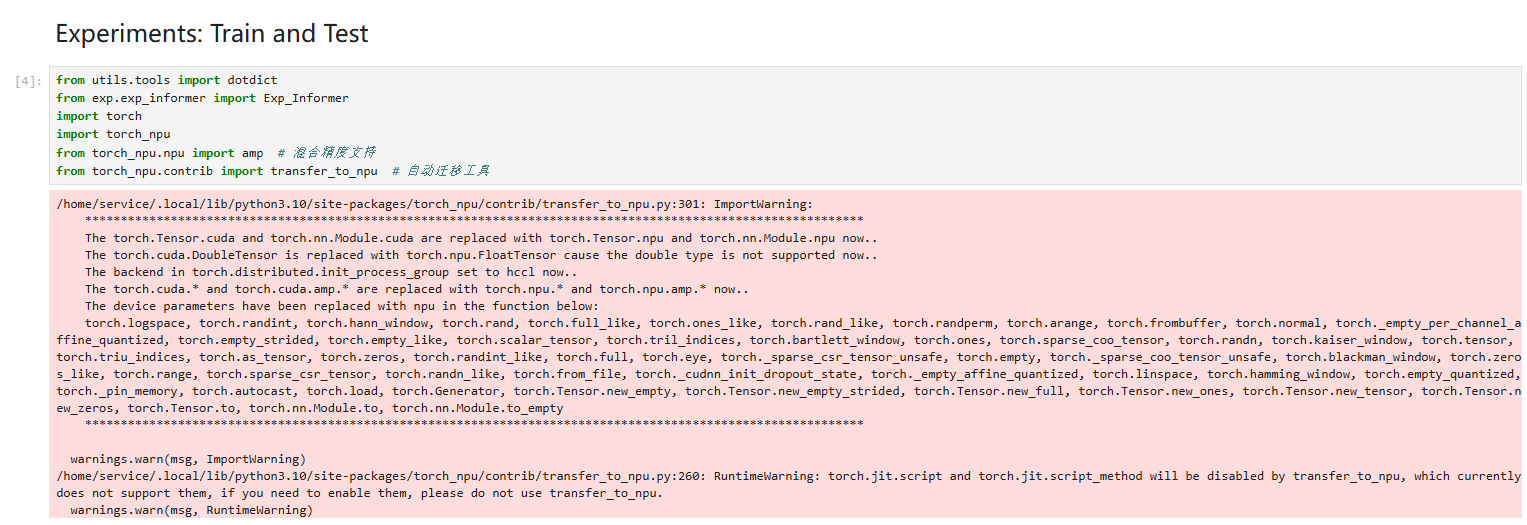
这里出现的警告告诉了自动迁移工具会对哪些代码进行修改。
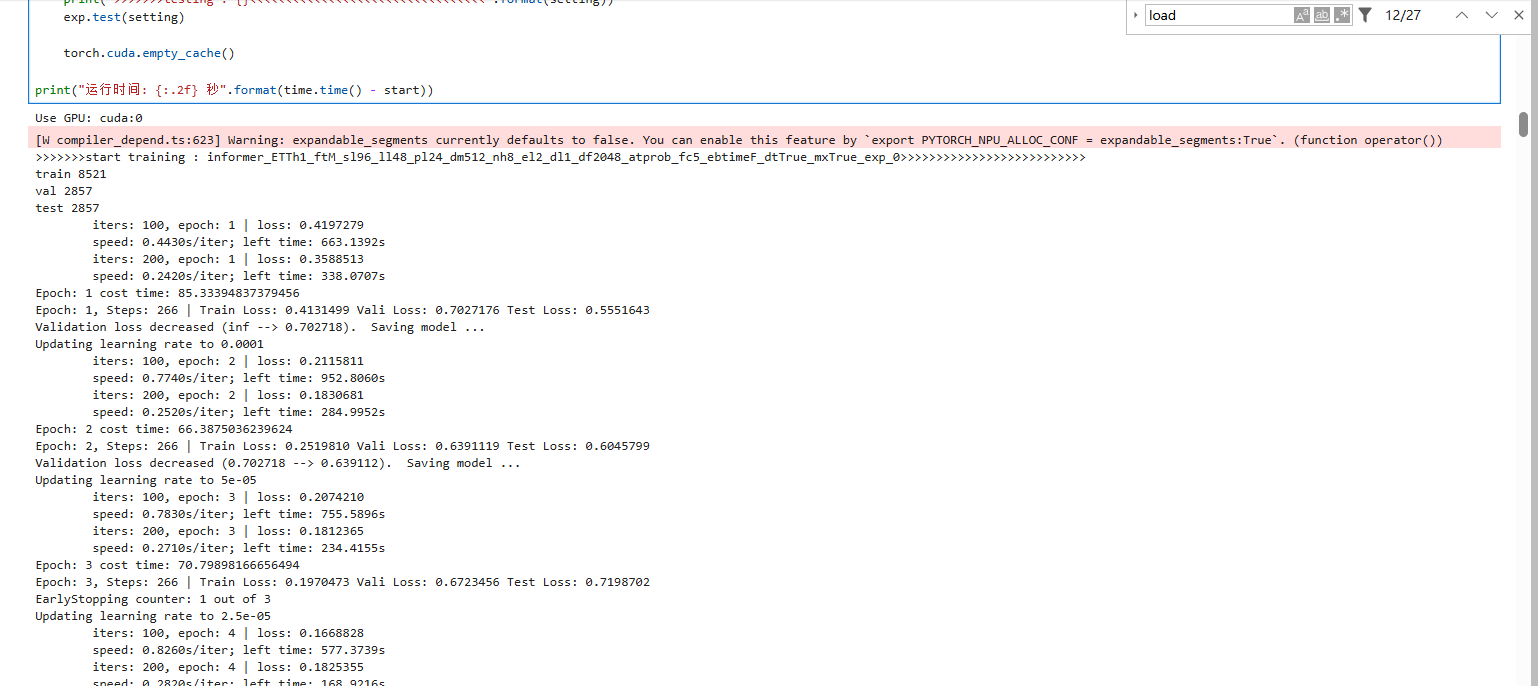
这里提示Use GPU实际上已经是调用的NPU了,因为内部代码已经完成替换。由于该机器没有NVIDIA显卡所以测试了CPU运行2000秒也没有运行完第一个Epoch,显然不可能调用的CPU:

经过测试只需要在Notebook添加三行代码,甚至不需要修改模型文件即可在华为NPU上运行Pytorch,Informer的Demo可以全部正常运行。方法一比较简单。
不过对比Colab整个测试跑完只要130s的水平来说,使用NPU的速度相比之下比较慢。原因可能是需要使用华为的Mindspore框架才能发挥全部能力。
2.将Pytorch移植到华为的Mindspore框架。
该方法较为复杂,几乎重构整个项目。
首先在本地调试开发环境:https://www.mindspore.cn/install/
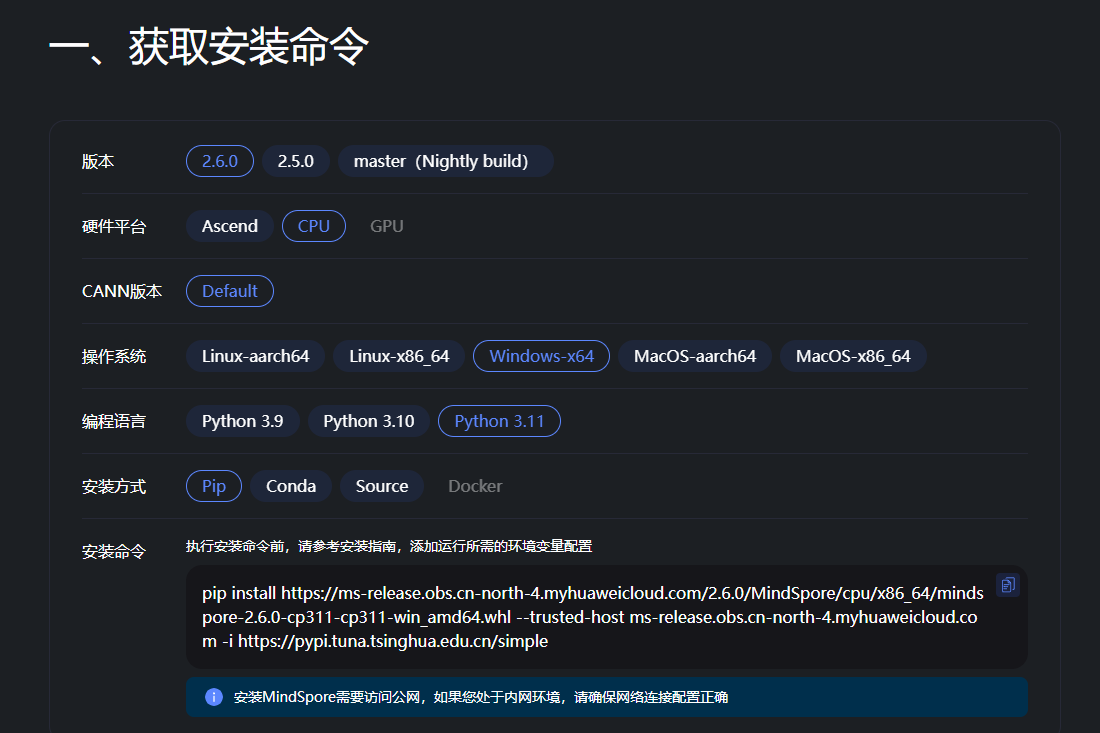
由于Mindspore不支持GPU,在本地用CPU跑通之后再放到云环境去运行。
在迁移之前,我想先做几个实验决定是否需要迁移,对比torch-npu和mindspore在华为Ascend设备上的性能
torch-npu vs mindspore
torch-npu:
mindspore:
目前这两个包都是正常维护的,甚至版本号都差不多,如果torch-npu和mindspore没有性能上的巨大的差异两个方案都是可选的。
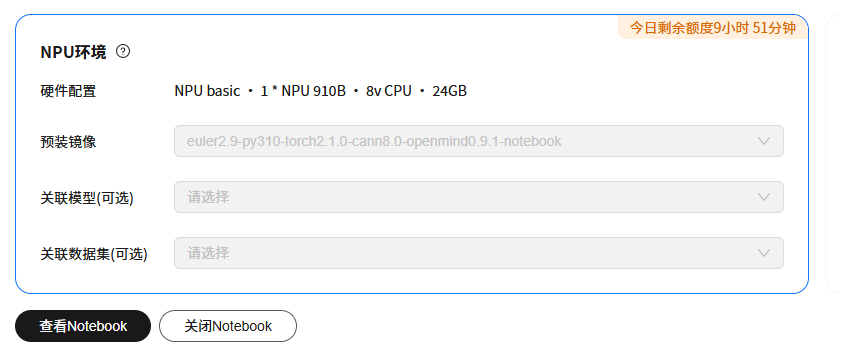
测试环境为华为官方的提供910B的Notebook环境,这里也默认提供了torch2.1.0环境:
偶然发现只要把机器开着到12点的刷新时间就可以在第二天获得10小时的用量。
运行了一个简单的性能对比脚本

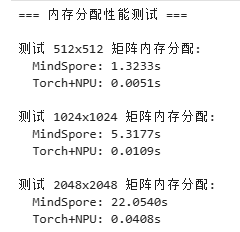

我感觉可能是代码的问题而不是Mindspore框架的问题。我不确定到底是哪里出问题导致的,但是可以排除mindspore使用CPU执行。
Symtime复现步骤
数据集准备:
在运行
python short_term_forecast.py
python long_term_forecast.py
这两个命令时一直发生报错一直在找问题,在原数据集官网下载页面下载的直接按照文件中指定的目录放置会出现各种的文件名和csv文件里的参数不匹配的问题,特别是M4数据集,提示缺少training.npz文件。
在仓库中搜索有没有预处理脚本无果,于是我想到找别的论文中也使用过该数据集的项目,然后找到也使用过M4数据集的TimesNet:https://github.com/thuml/TimesNet?tab=readme-ov-file项目,根据readme的指导进入了https://github.com/thuml/Time-Series-Library这个项目。
https://drive.google.com/drive/folders/13Cg1KYOlzM5C7K8gK8NfC-F3EYxkM3D2
这是Time-Series-Library项目中readme文件给出的的数据集下载地址。
将这里的给出的数据集下载放到datasets的文件夹里,数据集的问题解决了可以正常在GPU上跑通了。
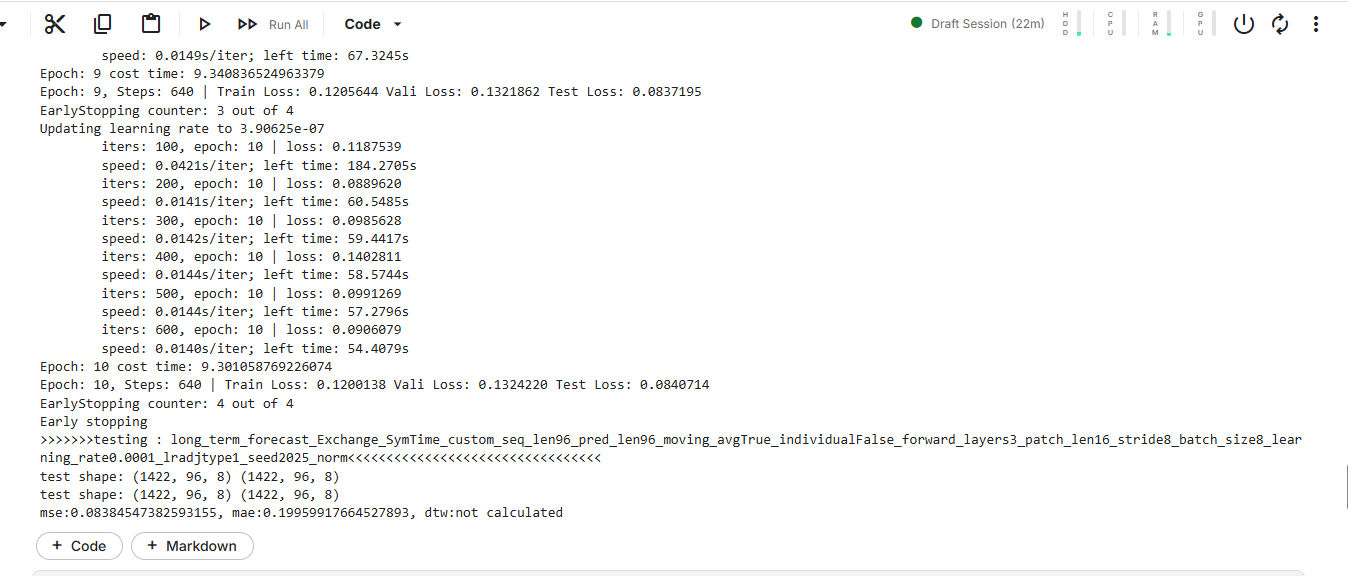
Test on NPU:
由于mindspore的转换比较复杂,目前还是采用的torch-npu的包进行测试,使用mindspore在尝试先复现一些较为简单的项目。
这是目前在华为NPU环境的运行测试,原先在Informer的Official Notebook里一样,只要加上三行转换代码就可以正常运行,代价是会有性能损失,在预计时间上来看,是Kaggle的P100 GPU速度的$1/2$。
每次运行时会出现一些警告信息:
python short_term_forecast.py
第一个实验是在控制台运行的,后续发现控制台会吞前面的输出,所以后面使用jupyter notebook。
python classification.py
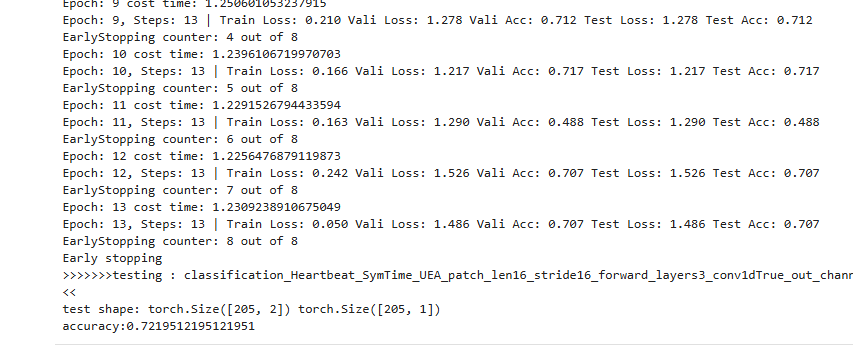
python imputation.py
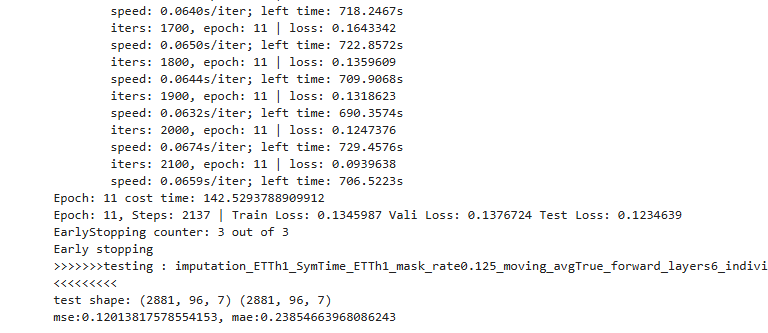
python long_term_forecast.py
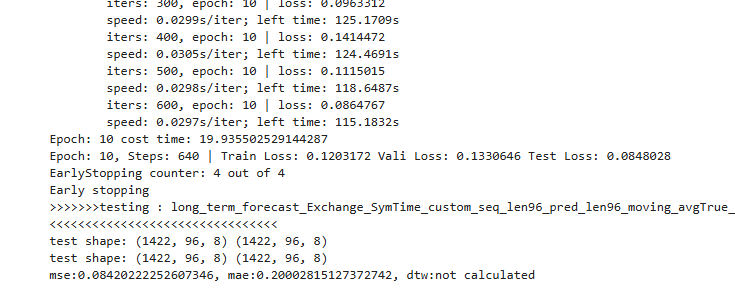
python anomaly_detection.py
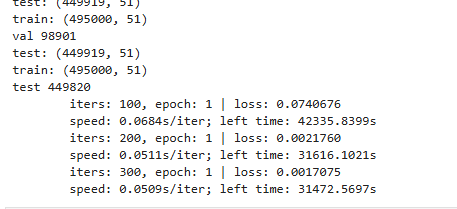
由于时间太长就没有继续这个测试。
总结
目前在华为Ascend上用torch-npu的替换包可以简单地将项目跑在NPU上。但是目前不清楚性能损失和华为自己的Mindspore框架有多少。以及两个框架的对齐问题也需要考虑。目前计划使用mindspore把Informer跑起来试试水,但是参考了有人移植过的Informer-mindspore:https://github.com/guolalala/Informer-MindSpore,mindspore版本为2.0.0,但是:

后续查看历史版本:
用pip直接安装whl也无法跑通这个项目,一直出现各种报错问题。
后续计划
1.从mindspore官方的程序包或者示例项目里找一些完善的实现进行实验和学习。
2.设计一个更完善的实验对比torch-npu和mindspore在NPU上的性能。

留下评论