
IDD-2504.3
Accelerate库实现多NPU
DDP:
DDP(Distributed Data Parallel)是PyTorch提供的分布式训练解决方案,允许在多个GPU或多个节点上并行训练深度学习模型。
Accelerate:
Accelerate是Hugging Face开发的库,旨在简化分布式训练的复杂性,提供统一的API来处理单GPU、多GPU、TPU等不同硬件配置。
关系
1.DDP是底层的分布式训练框架
2.Accelerate是高层封装,内部可以使用DDP作为后端
3.Accelerate提供更简单的API,减少了样板代码
由于本项目实现的是Accelerate库的方法,所以想知道有没有最小化修改的方法来适配NPU。
在找了很多方法之后,想到既然已经完全适配了DDP的方法,Accelerate基于DDP封装,那么是不是Accelerate已经被适配了,想到会不会文档里有accelerate迁移指南,没想到已经适配了Accelerate的NPU支持。藏在文档的很深处有一个段话:
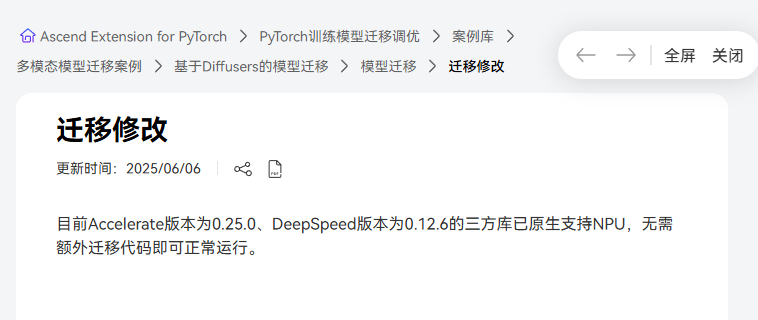
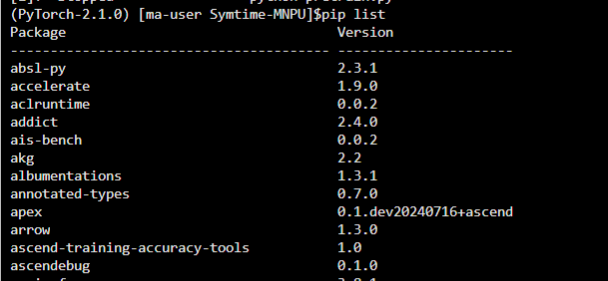
经过pip list查询,Accelerate的版本已经是远高于0.25.0了:
问题1:Accelerate运行方式
在Kaggle提供的T4$\times$2 GPU,运行时没有关注到底是不是双卡在运行,导致了一些问题。
我像别的平台一样直接运行:
python pretrain.py
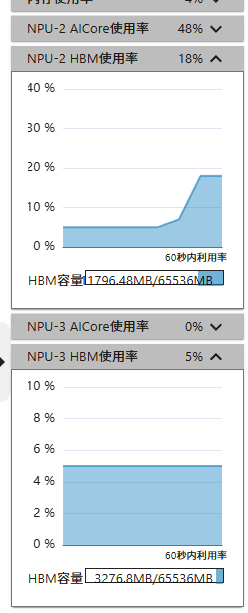
只有一个NPU在运行。经过学习之后直到这里的原因是没有使用accelerate来启动脚本。
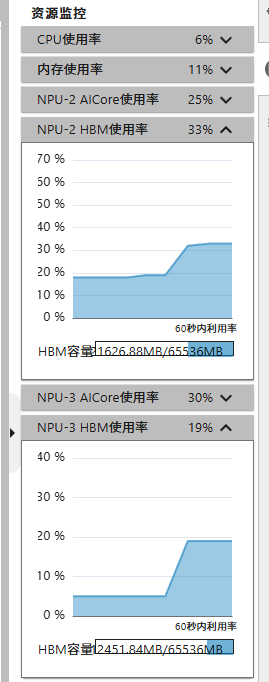
accelerate launch --num_processes 2 pretrain.py
使用如上脚本可以启用双NPU。如下图所示:
问题2:出现第一个报错
问题描述:
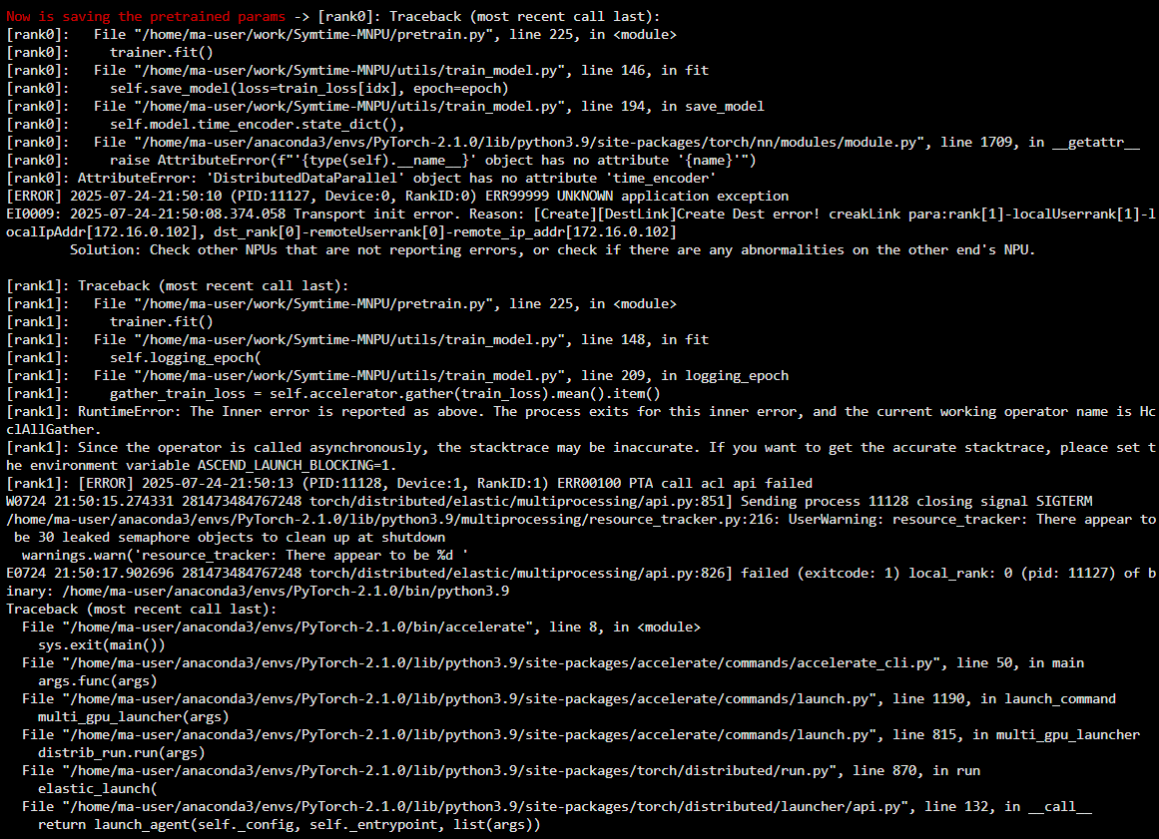
通过日志发现
gather_train_loss = self.accelerator.gather(train_loss).mean().item()
这一行代码引发了后面的报错,观察这行代码的作用,只是作为记录用,所以一个简单的方法是删掉或者给它们赋一个常值,不影响训练和控制台的log:

问题3:出现第二个报错
问题描述:
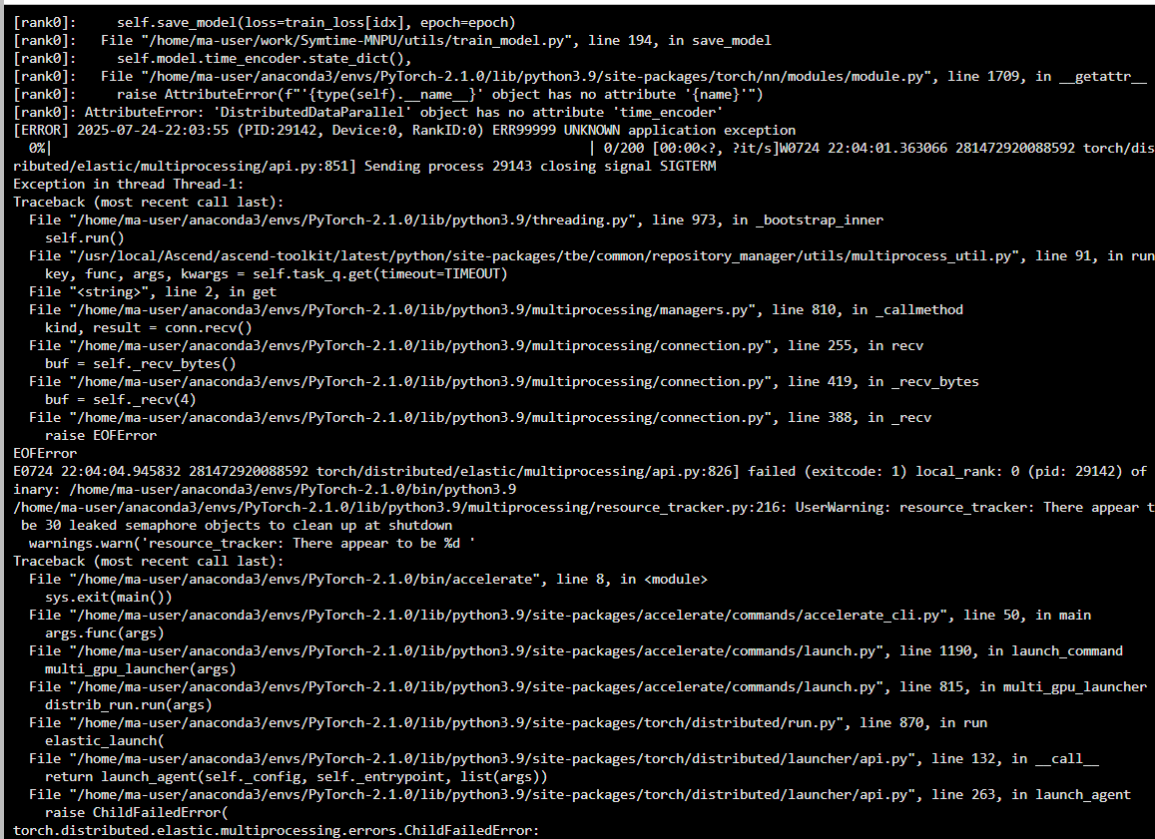
File "/home/ma-user/work/Symtime-MNPU/utils/train_model.py", line 146, in fit
[rank0]: self.save_model(loss=train_loss[idx], epoch=epoch)
[rank0]: File "/home/ma-user/work/Symtime-MNPU/utils/train_model.py", line 194, in save_model
[rank0]: self.model.time_encoder.state_dict(),
[rank0]: File "/home/ma-user/anaconda3/envs/PyTorch-2.1.0/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1709, in __getattr__
[rank0]: raise AttributeError(f"'{type(self).__name__}' object has no attribute '{name}'")
[rank0]: AttributeError: 'DistributedDataParallel' object has no attribute 'time_encoder'
观察日志发现在194行出现报错:
self.model.time_encoder.state_dict()
因为要在model的module里访问time_encoder
所以应该改为:
self.model.module.time_encoder.state_dict()
运行测试
accelerate launch --num_processes 2 pretrain.py --batch_size 50
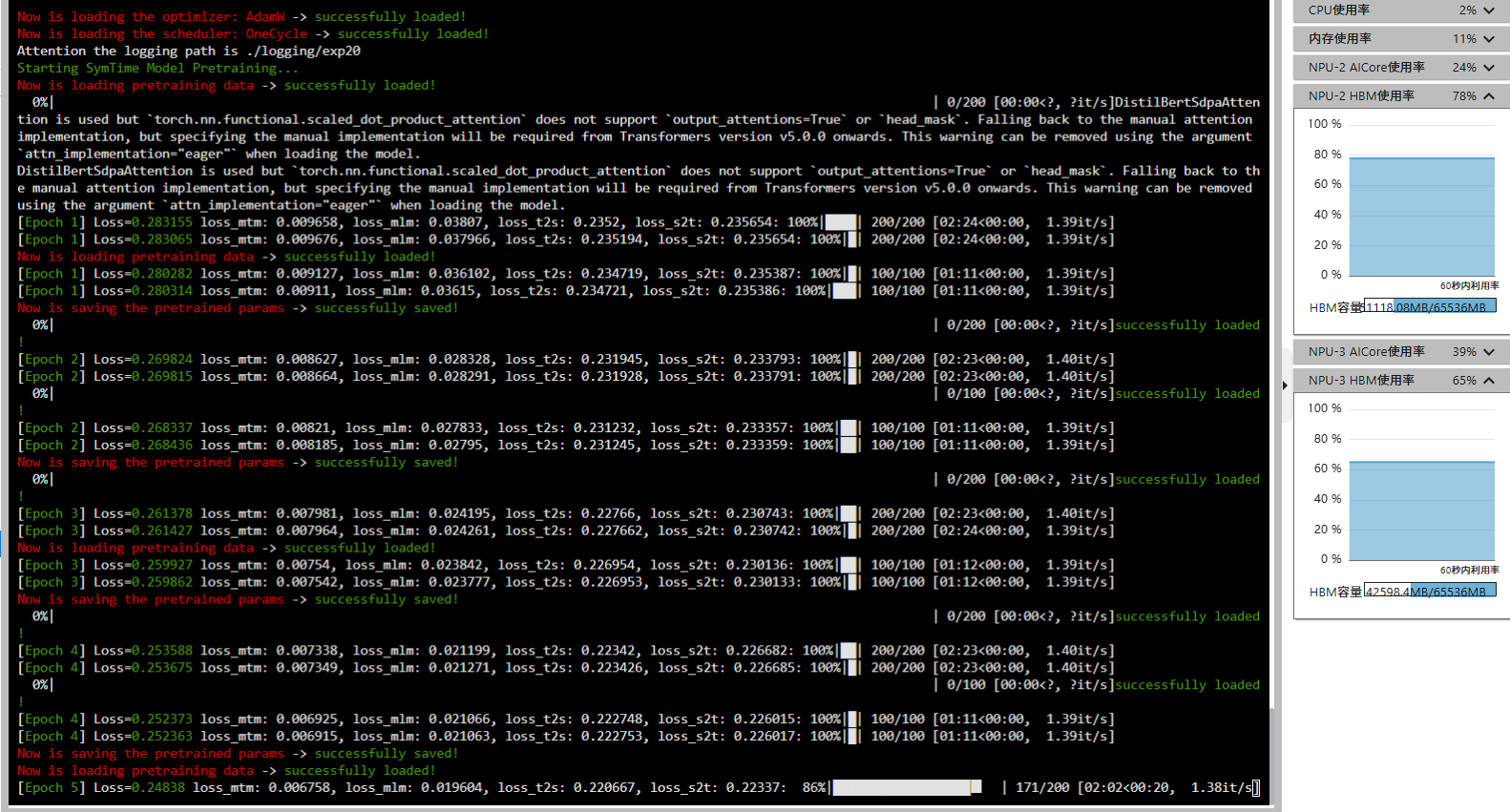
目前来看一切正常。
如果要8卡运行就是
accelerate launch --num_processes 8 pretrain.py --batch_size 75
batch_size在75-80左右可以几乎占满64GB的显存。
Kaggle平台的cuda版本
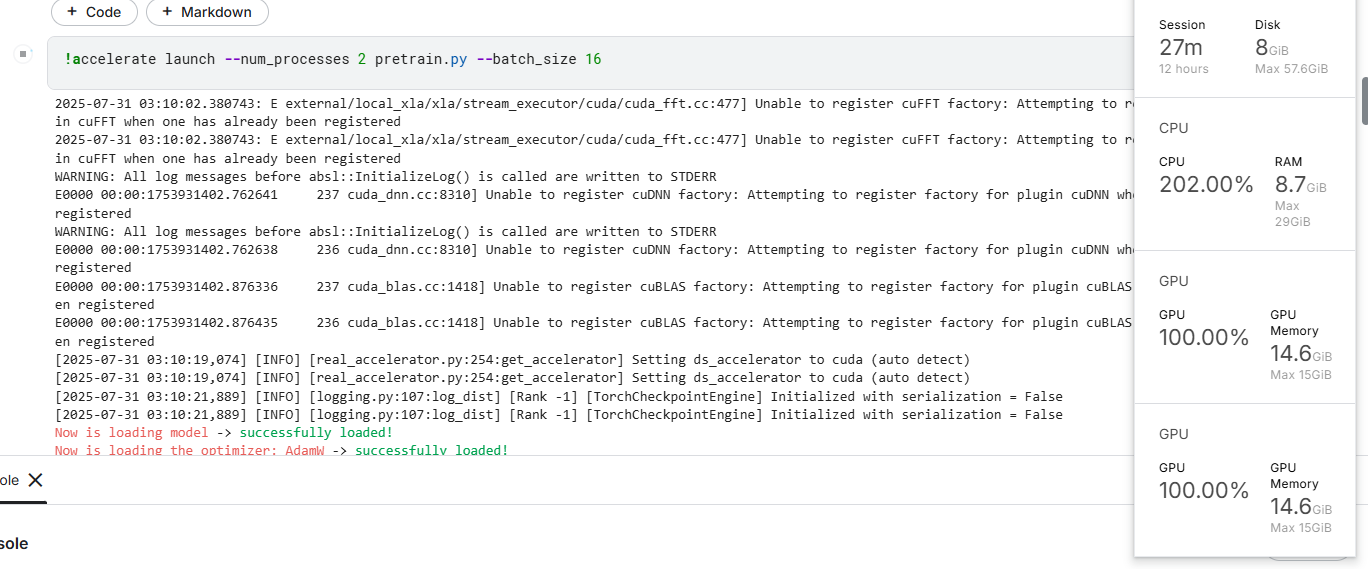
经过测试使用相同的accelerate的指令可以正常启动两个GPU。
速度对比:
| 设备 | T4$ \times $2 | 910B$ \times $2 |
|---|---|---|
| 分钟/epoch | 20 | 3 |
一致性对比
由于设置了fixed_seed参数,我很好奇在这NPU和CUDA两个平台上的训练出来的参数是否一致?
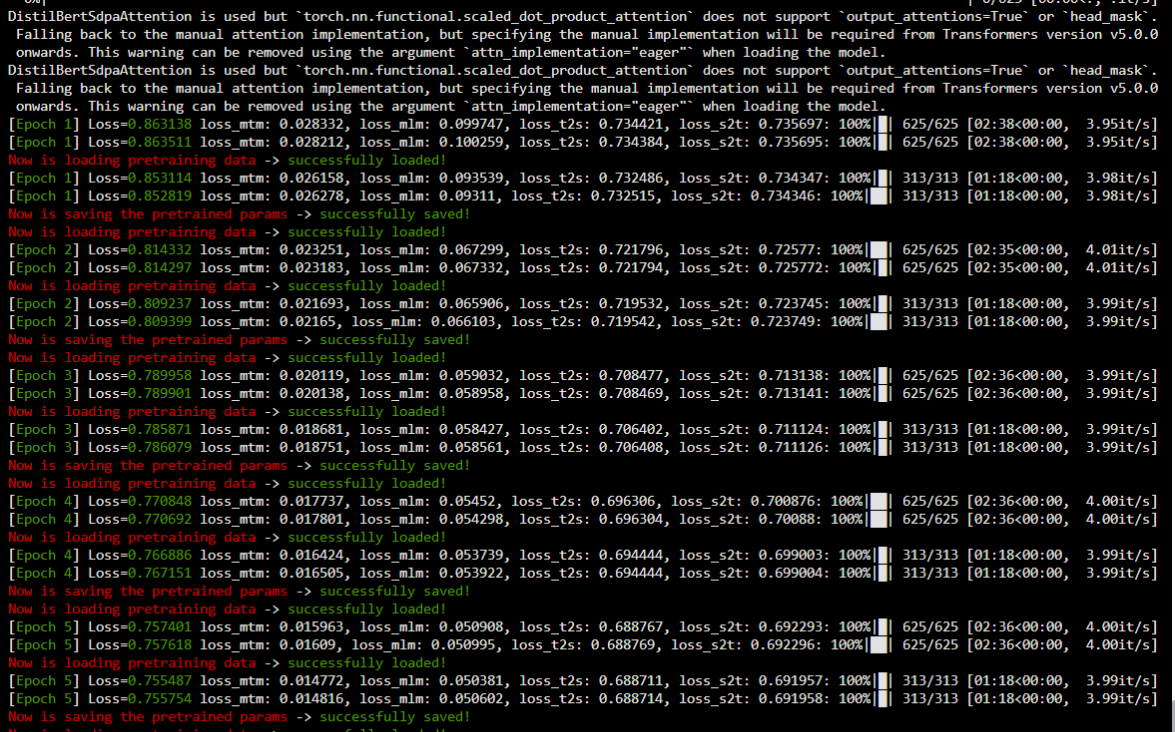

| Epoch | NPU Loss | T4 Loss | 绝对差值(Abs Diff) | 相对误差(Rel Diff %) |
|---|---|---|---|---|
| 1 | 0.852819 | 0.852445 | 0.000374 | 0.0439% |
| 2 | 0.809399 | 0.809326 | 0.000073 | 0.0090% |
| 3 | 0.786079 | 0.785699 | 0.000380 | 0.0483% |
| 4 | 0.767151 | 0.766967 | 0.000184 | 0.0240% |
| 5 | 0.755754 | 0.755860 | 0.000106 | 0.0140% |
总的来说,这些微小误差是合理的、预期内的,不会影响整体实验结论。
总结
目前:
1.https://blog.skyai.best/2025/07/24/IDD-2504.2.html完整说明了构建华为云NPU环境、上传文件OBS系统、迁移NPU的最简单的步骤。
2.这周完整测试了双卡的运行脚本和说明了需要修改的地方,测试了NPU与GPU双卡环境的参数训练结果的一致性,结论是在底层改变的情况下训练的结果几乎没有显著差异。
3.可以在保证框架结构不变的情况下迁移到NPU获得较大的显存和训练速度收益。
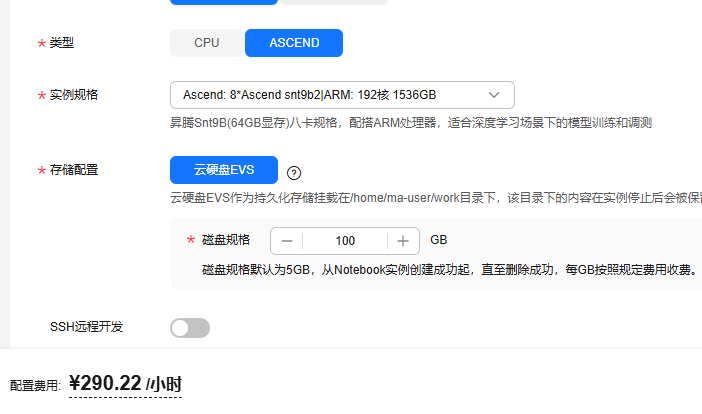
4.目前在双卡环境进行测试,使用原本的accelerate库所以八卡理论上也只要改一下参数即可,因为八卡910B2每小时价格高达290¥,现在的余额够用3200小时左右,所以测试环境都是基于双卡910B2。
最高可用的实例规格:

留下评论