
Weekly post 2
Informer&&Symtime&&云GPU和云Jupyter notebook平台学习
给笔记本配置了新的显示器,电脑很久没有清灰,感觉电脑的发热和卡顿明显增多,尤其是开了许多的网页和编辑器和终端的情况下,清完灰换了相变片之后温度明显下降,但是受制于性能瓶颈,还是需要有更多的计算资源,于是我想到可以使用Colab来加速测试过程。
最近家里宽带有些问题,经常出现在下载速度高了就断网的情况,已经报修:
在许多项目的Github仓库的readme中,都会包含一个Colab的网页。在Colab上可以直接运行给出的Jupyter notebook代码,不需要进行环境的配置。
Colab还提供了免费的GPU运算额度,经过测试一天使用时间在4个小时不到。于是我想还有没有类似的平台提供该类服务,在寻找筛选之后发现,比较知名的还有Kaggle Notebook和Azure ML提供免费的服务。Kaggle提供每周30小时的GPU时间,Azure ML每年在学生100$的免费额度下可以使用最低档位下使用200小时。有了云Notebook可以在同时运行更多的测试。
接下来对免费版Colab、免费版Kaggle、笔记本电脑(3060)的配置和使用方法进行学习。
性能对比
运行Informer给的Notebook的Demo:
| 设备 | 运行时间(s) |
|---|---|
| 3060 Laptop | 124.05 |
| Colab T4 | 138.31 |
| Kaggle P100 | 112.86 |
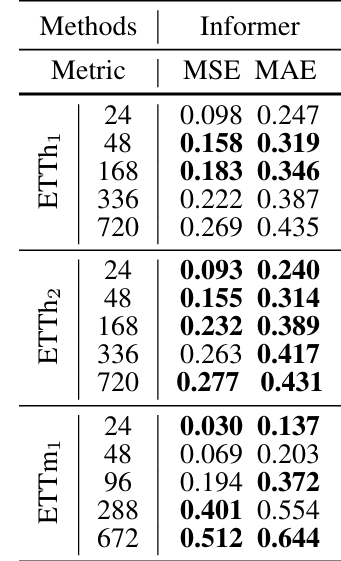
这是论文中给出的部分测试结果
Kaggle平台与Colab平台的测试结果:
| 数据集 | 预测长度 | MSE | MAE | RMSE |
|---|---|---|---|---|
| ETTh1 | 24 | 0.6357 | 0.6000 | 0.7973 |
| ETTh1 | 48 | 0.8185 | 0.7005 | 0.9047 |
| ETTh1 | 168 | 0.9640 | 0.7786 | 0.9818 |
| ETTh1 | 336 | 1.1763 | 0.8756 | 1.0846 |
| ETTh2 | 24 | 1.3892 | 0.9611 | 1.1786 |
| ETTh2 | 48 | 2.1600 | 1.2189 | 1.4697 |
| ETTh2 | 168 | 6.8503 | 2.2826 | 2.6173 |
| ETTh2 | 336 | 4.4858 | 1.8274 | 2.1180 |
| ETTm1 | 24 | 0.3025 | 0.3742 | 0.5500 |
| ETTm1 | 48 | 0.5196 | 0.4703 | 0.7208 |
| ETTm1 | 168 | 0.7538 | 0.6615 | 0.8682 |
| ETTm1 | 336 | 1.0016 | 0.7893 | 1.0008 |
Colab平台的测试结果
| 数据集 | 预测长度 | MSE | MAE | RMSE |
|---|---|---|---|---|
| ETTh1 | 24 | 0.5722 | 0.5435 | 0.7564 |
| ETTh1 | 48 | 0.6950 | 0.6297 | 0.8337 |
| ETTh1 | 168 | 1.0641 | 0.8298 | 1.0316 |
| ETTh1 | 336 | 1.2859 | 0.9411 | 1.1340 |
| ETTh2 | 24 | 1.6263 | 1.0139 | 1.2753 |
| ETTh2 | 48 | 2.3825 | 1.2277 | 1.5435 |
| ETTh2 | 168 | 7.8719 | 2.4882 | 2.8057 |
| ETTh2 | 336 | 4.0247 | 1.6424 | 2.0062 |
| ETTm1 | 24 | 0.3182 | 0.3720 | 0.5641 |
| ETTm1 | 48 | 0.4842 | 0.4778 | 0.6958 |
| ETTm1 | 168 | 0.7566 | 0.6500 | 0.8699 |
| ETTm1 | 336 | 0.9910 | 0.7846 | 0.9955 |
测试代码colab:https://colab.research.google.com/drive/1yvJIiRkTU_nk09yiUEQ-buKMo3yxUXIC#scrollTo=CDHF-HerAE3u
经过测试发现Kaggle提供的计算速度是最快的。Colab的计算速度较慢。
该代码未设置fix_seed,所以每次的结果都会不一样,但是整体趋势是一致的。
Encoder-Decoder架构改进
Informer结构:
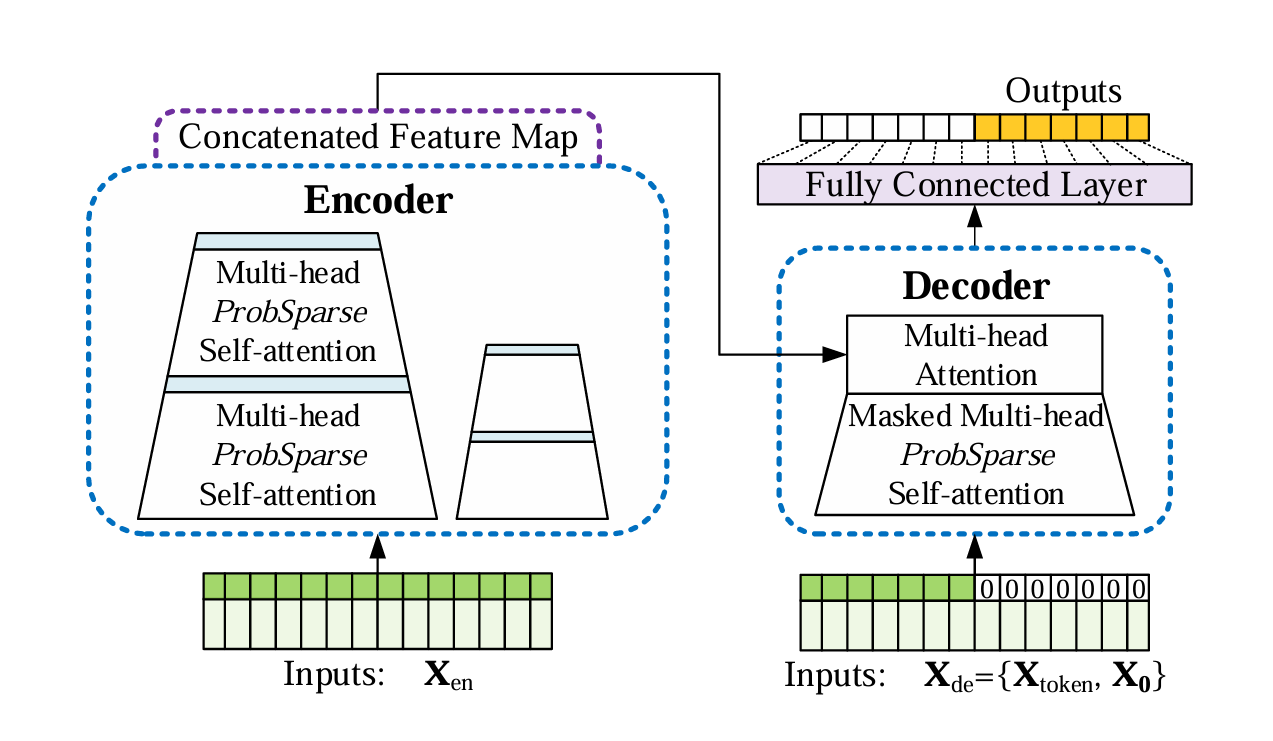
Transformer结构:
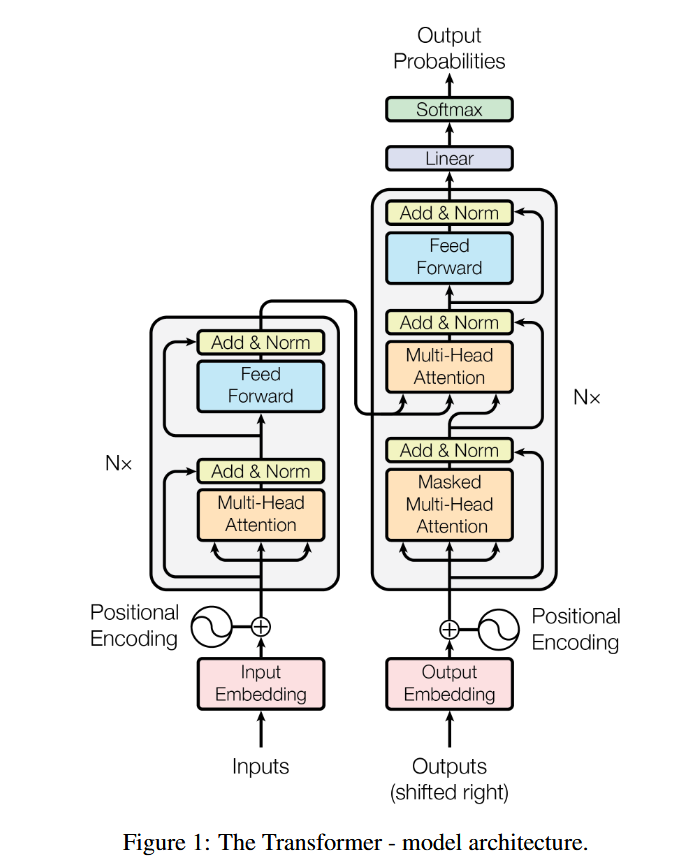
Transformer一次输出一个值,Informer一次可以输出一整个序列。
新任务
1.学习从NVIDIA CUDA移植到ASCEND NPU。
云Notebook+1:
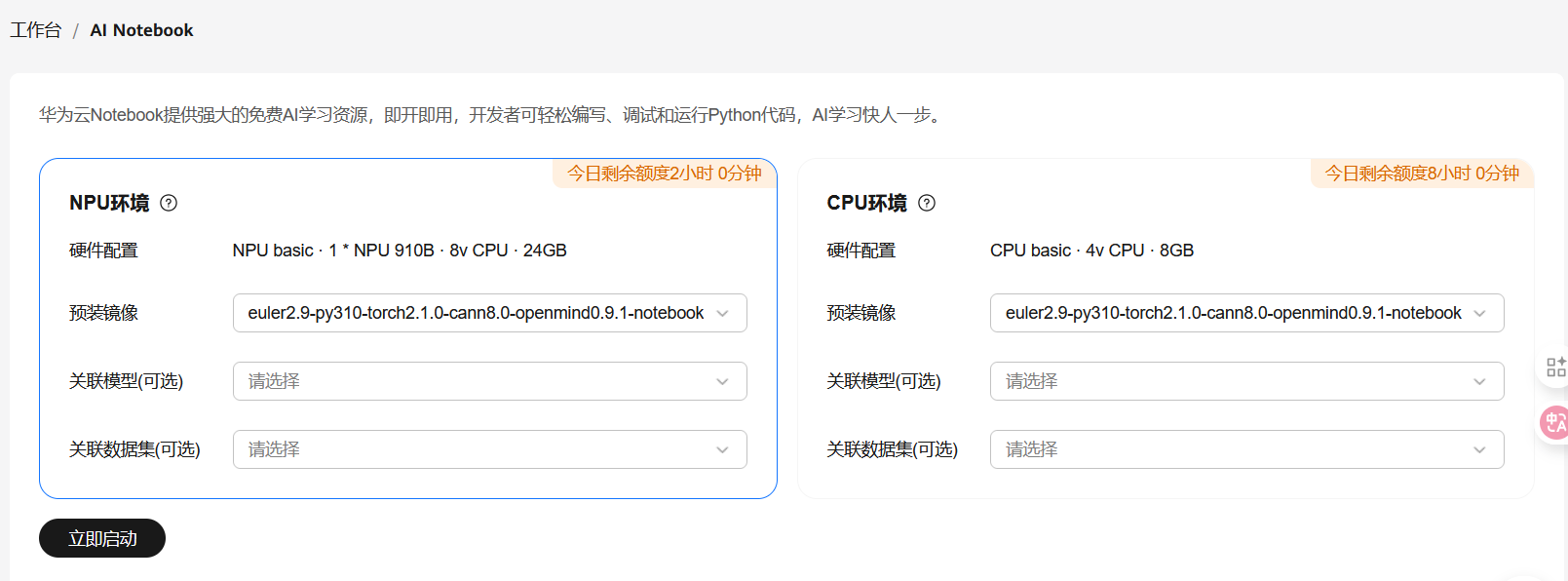
华为云提供每天2小时的NPU使用额度。
NPU性能测试:使用自带的模型示例跑了一遍Deepseek-R1-distil-Qwen-7B:

配置环境让SymTime在本地运行
环境问题:deepspeed包在windows环境下始终无法安装,显示无法import torch,但是我重复下载并测试了多个torch和python版本,始终无法使用pip安装。
经过寻找方法,一致指向使用Linux环境来运行。在windows上有著名的WSL,于是我开始调试WSL环境。
WSL配置
先把WSL从C盘换到E盘
导出现有发行版为 .tar 文件:
wsl --export Ubuntu E:\WSL\ubuntu_backup.tar
注销(删除)原有 WSL 实例:
wsl --unregister Ubuntu
从备份文件重新导入到新位置:
wsl --import Ubuntu E:\WSL\Ubuntu D:\WSL\ubuntu_backup.tar --version 2
然后是常规的apt update
sudo apt update && sudo apt upgrade -y
问题:因为以往在VPS/VM上运行这个命令时,即使是1C1G的服务器速度也是很快。但是在本地运行出现了ign 1的问题。
解决方法:配置代理接口:
首先查看当前的主机的局域网IP:
ipconfig
找到WSL的IPv4地址
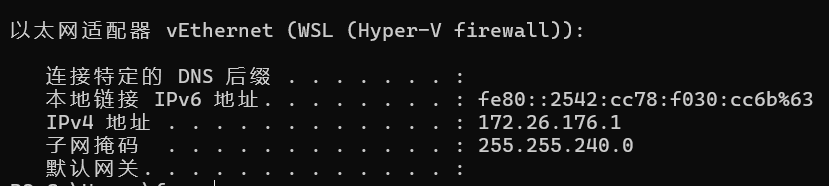
export ALL_PROXY="socks5h://172.26.176.1:10808"
export http_proxy=$ALL_PROXY
export https_proxy=$ALL_PROXY
配置为windows中的局域网代理端口10808
让APT也走代理:
sudo nano /etc/apt/apt.conf.d/99proxy
编辑为:
Acquire::http::Proxy "socks5h://172.26.176.1:10808";
Acquire::https::Proxy "socks5h://172.26.176.1:108089";
至此可以快速地进行apt安装过程。
测试nvidia-smi
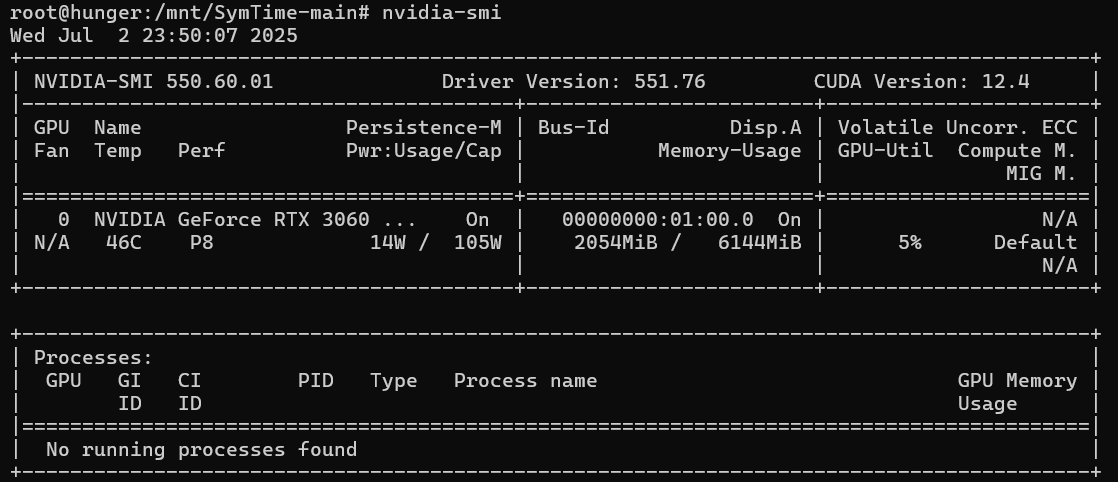
安装对应版本的Pytorch:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt

Deepspeed成功安装。
Symtime模型运行配置:
首先是pretrain.py:
需要有m4数据集和pretrained_data放置在dataset目录下
由于网络问题需要自行下载distilbert-base-uncased模型:https://huggingface.co/distilbert/distilbert-base-uncased
WSL运行
WSL文件管理:
在windows管理器里输入:
\\wsl$\
进入WSL的文件系统。使用VScode打开,把项目复制进去,配置好目录,开始测试:
python3 pretrain.py

下一步计划
1.学习华为NPU的开发环境。
2.将Symtime项目尝试跑在NPU上。

留下评论