
[论文分享] Arxiv 2025 SEAL:大型语言模型如何实现“自我进化”与持续适应
| 标题 | Self-Adapting Language Models (SEAL) |
|---|---|
| 作者 | Adam Zweiger, Jyothish Pari, Han Guo, Ekin Akyürek, Yoon Kim, Pulkit Agrawal |
| 机构 | Massachusetts Institute of Technology (MIT) |
| 论文 | https://arxiv.org/abs/2506.10943v1 |
| 代码 | https://github.com/Continual-Intelligence |
摘要
大型语言模型(LLMs)在处理复杂任务时展现出卓越的能力,但其核心挑战在于,一旦预训练完成,模型权重便趋于静态,难以有效适应不断涌现的新任务、新知识或新示例。本文提出“自适应语言模型”(Self-Adapting LLMs, SEAL)框架,它颠覆了传统LLM的静态范式,赋予模型通过自主生成微调数据和更新指令来实现“自我进化”的开创性能力。SEAL的核心机制在于,当模型接收到新输入时,它能够智能地生成“自我编辑”(self-edits)。这些自我编辑不仅可以巧妙地重构信息,还能精确指定优化超参数,甚至能灵活调用外部工具进行数据增强和基于梯度的权重更新。通过监督微调(SFT)的应用,这些自我编辑能够转化为模型持久的权重更新,从而实现长期的、根本性的适应。为了确保模型能够生成高效的自我编辑,SEAL巧妙地引入了一个强化学习(RL)循环,将更新后模型在下游任务上的表现作为奖励信号,持续优化自我编辑的生成策略。与以往依赖独立适应模块或辅助网络的方法截然不同,SEAL直接利用模型自身强大的生成能力来参数化和控制其整个适应过程,这使得整个框架更加简洁、高效且具备更强的通用性。在知识整合和少样本泛化等关键应用领域的实验结果强有力地证明,SEAL是推动语言模型迈向自我导向适应的里程碑式进展,预示着LLMs未来将能够更加智能、自主地响应新数据和新挑战。
1 引言:LLM的“静态”困境与“自我进化”的愿景
大型语言模型(LLMs)凭借其在海量文本语料库上的预训练,在语言理解和生成方面取得了令人瞩目的成就,成为人工智能领域的重要基石。然而,在将这些强大的模型应用于特定任务、整合最新信息或掌握复杂推理技能时,我们却面临着一个核心挑战:任务特定数据的稀缺性。传统的LLM在预训练完成后,其内部知识和能力便相对固定,难以灵活地适应动态变化的世界。
本文深入探讨了一个的假设:LLM能否像人类学习者一样,通过主动转换或生成自身的训练数据和学习过程,从而实现真正的“自我适应”?
我们可以将这一愿景类比为一名人类学生为机器学习期末考试做准备的过程。优秀的学习者往往不会仅仅依赖原始的课堂笔记或教科书内容,而是会主动对信息进行整理、重构,甚至以自己的理解方式重新撰写笔记。这种对外部知识的重新解读、增强和内化,使其更易于理解和记忆,从而显著提升了学生理解内容和回答问题的能力。这种“自我学习”和“知识重构”的现象并非仅限于考试,而是人类在各种学习任务中普遍存在的有效策略。SEAL框架正是受到了这种深层“自我学习”机制的启发,旨在打破LLM的静态壁垒,赋予其主动学习和适应的能力。
当前,LLMs通常通过微调(finetuning)或上下文学习(in-context learning)来从任务数据中学习。然而,这些数据可能并非总是以最佳格式或最佳数量呈现,且现有方法往往无法让模型开发出定制化的策略来高效地转换和学习训练数据。为了突破这一瓶颈,SEAL框架应运而生,其核心目标是赋予LLMs自主生成训练数据和微调指令的能力,从而实现更高效、更灵活的自我适应。
2 方法:SEAL框架的核心机制——双层优化循环
SEAL框架的精髓在于其巧妙设计的双层优化循环,这一机制使得LLMs能够通过生成和应用“自我编辑”来持续改进自身,实现动态适应和性能提升。
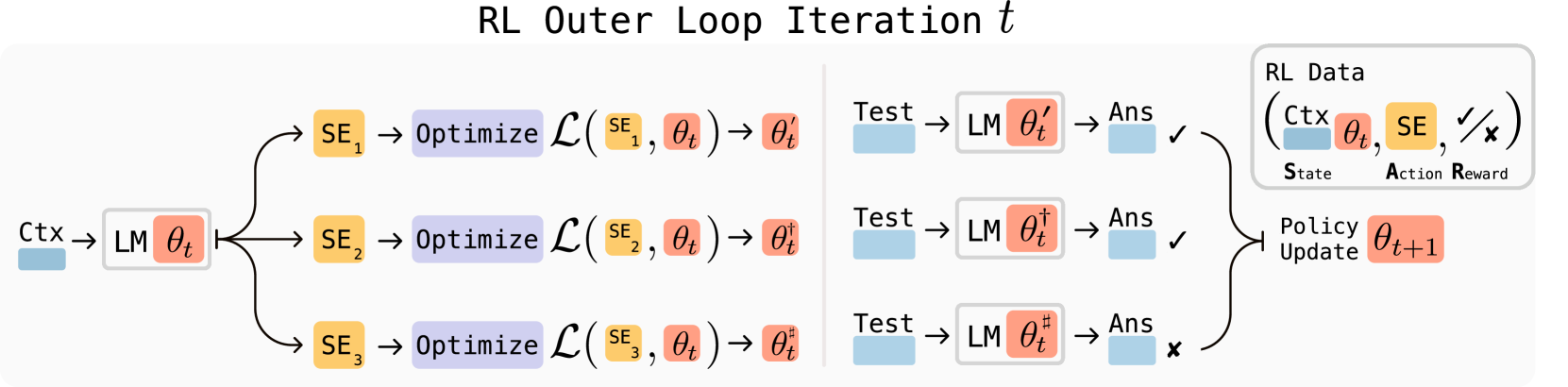
图 1:SEAL 框架概览。在每一次强化学习(RL)外循环迭代中,模型会生成候选的自我编辑(SE)——即关于如何更新权重的指令,随后应用这些更新,并在下游任务上评估性能。根据评估结果产生的奖励信号,用于优化自我编辑生成策略。
2.1 自我编辑(Self-Edits)的生成与应用
当LLM接收到新的输入(例如,一段需要整合的新知识或一个需要解决的新任务)时,它不再被动地等待外部指令,而是主动地生成一个或一系列“自我编辑”(SE)。这些自我编辑是模型以自然语言形式输出的指令,其内容和功能高度灵活,可以包括:
- 信息重构与转换:模型可以根据新输入的特点,以不同方式重新组织、提炼或转换信息,生成更适合模型内部学习的训练数据。例如,将一段描述性文本转化为问答对,或将复杂概念简化为原子事实。
- 优化超参数的智能指定:自我编辑可以精确地指定微调过程中的关键优化超参数,如学习率(learning rate)、训练轮次(training epochs),甚至是对特定token类型进行选择性损失计算的指令。这种能力使得模型能够根据任务特性,动态调整学习策略。
- 外部工具的灵活调用:SEAL框架允许模型通过自我编辑调用预定义的外部工具。这些工具可以用于数据增强(例如,对图像进行旋转、翻转、缩放等操作),或执行基于梯度的权重更新。这种工具调用机制极大地扩展了模型的适应能力边界。
这些生成的自我编辑随后通过监督微调(Supervised Finetuning, SFT)机制应用于模型。SFT过程将自我编辑转化为模型参数的实际更新($θ’ ← SFT(θ, SE)$),从而实现模型权重的持久性修改。这意味着模型的学习不再是短暂的上下文记忆,而是能够长期地内化新知识和新技能,实现根本性的适应。
2.2 强化学习(RL)循环:优化自我编辑生成策略
为了确保模型能够生成高质量、高效的自我编辑,SEAL引入了一个创新的强化学习(RL)循环。这个外层RL循环负责优化模型生成自我编辑的策略,其工作流程如下:
-
候选自我编辑的生成:在每个RL外层循环迭代中,模型根据当前上下文C生成一系列候选的自我编辑($SE$~$LM_θ(· C)$)。 - 内层更新循环:对于每个生成的自我编辑,模型会进入一个内层更新循环。在这个循环中,自我编辑被应用于模型,进行权重更新($θ’ ← SFT(θ, SE)$)。
-
下游任务性能评估:更新后的模型($LM_{θ’}$)在特定的下游任务τ上进行评估,以衡量其适应效果($Ans ~ LM_{θ’}(· τ)$)。 - 奖励信号的计算:根据更新后模型在下游任务上的表现,计算一个奖励信号r($r ← r(Ans, τ)$)。这个奖励信号直接反映了自我编辑的有效性。
- 自我编辑策略的优化:模型利用这个奖励信号,通过最大化预期奖励来不断优化其生成自我编辑的策略。SEAL采用了一种名为ReSTEM的简单而有效的方法(一种基于过滤行为克隆的策略),来处理RL训练中的不稳定性问题,并优化目标函数。
与以往依赖独立适应模块或辅助网络的方法截然不同,SEAL的独特之处在于它直接利用模型自身强大的生成能力来参数化和控制其整个适应过程。这意味着模型不再需要额外的、独立的“学习模块”,而是将“学习如何学习”的能力内化到其自身的生成机制中,从而使得整个框架更加简洁、高效且具备更强的通用性。这种“元学习”(meta-learning)的范式使得SEAL能够学习如何从任务上下文中高效地进行学习。
我们使用强化学习优化自我编辑的生成过程:模型执行一个动作(即生成 SE),根据更新后的模型 $LM_{θ’} $在 $\tau$ 上的表现获取奖励 r,并更新策略以最大化期望奖励: \(\mathcal{L}_{\mathrm{RL}}\left(\theta_{t}\right):=-\mathbb{E}_{(\mathcal{C}, \tau) \sim \mathcal{D}}\left[\mathbb{E}_{\mathbf{SE} \sim \mathrm{LM}_{\theta_{t}}(\cdot \mid \mathcal{C})}\left[r\left(\mathbf{SE}, \tau, \theta_{t}\right)\right]\right] \tag1\) 本文采用了 ReSTEM方法,它基于过滤后的行为克隆,也被称为拒绝采样 + 微调(SFT)。
ReSTEM 可以被看作一个期望最大化(EM)过程:
- E 步:从当前模型策略中采样候选输出;
- M 步:仅对获得正奖励的样本进行监督微调。
这种方式在二值奖励下优化了目标函数 (1) 的一个近似版本:
\[r(\mathrm{SE}, \tau, \theta_t) = \begin{cases} 1 & \text{If on } \tau, \text{adaptation using SE improves } \mathrm{LM}_{\theta_t}\text{'s performance} \\ 0 & \text{Otherwise} \end{cases} \tag2\]3 实验与成果:SEAL在两大领域的卓越表现
SEAL框架在两个具有代表性的应用领域进行了严格的评估:知识整合(Knowledge Incorporation)和少样本泛化(Few-Shot Generalization)。这两个领域分别代表了模型适应的两种互补形式:将新信息融入模型权重以便无需上下文即可回忆,以及在仅见过少量示例后泛化到新任务的能力。
3.1 知识整合:超越GPT-4.1的知识内化能力
在知识整合任务中,SEAL旨在将新的事实性知识(例如来自SQuAD数据集的段落)高效地融入LLM的内部知识库。传统的做法是直接在原始段落文本上进行微调。然而,SEAL采取了更智能的策略:它在自身生成的合成数据上进行微调。
实验结果:
-
显著性能提升:在SQuAD数据集的无上下文问答任务上,经过RL训练后,在SEAL生成的合成数据上进行微调,显著提升了模型表现,准确率从基线的33.5%跃升至47.0%。
-
超越GPT-4.1:更令人惊讶的是,尽管SEAL模型本身规模相对较小(例如Qwen2.5-7B),但其生成的合成数据在效果上甚至超越了由GPT-4.1生成的合成数据(GPT-4.1合成数据带来的准确率为46.3%)。这强有力地证明了SEAL通过RL优化生成合成数据的有效性。
-
持续预训练的泛化能力:在持续预训练(CPT)设置下(模型需要从200个段落中整合信息),SEAL同样表现出色,达到了43.8%的准确率,再次超越了所有基线方法。这表明SEAL发现的编辑策略能够泛化到更复杂的、多段落的知识整合场景。

图 2 :知识融合设置。 给定一段新文本,模型生成该段内容的“蕴含句”。我们随后使用 LoRA 对这些输出进行微调。更新后的模型会在无原文可读的情况下回答与该段落相关的问题,回答的准确度即作为强化学习的奖励信号。
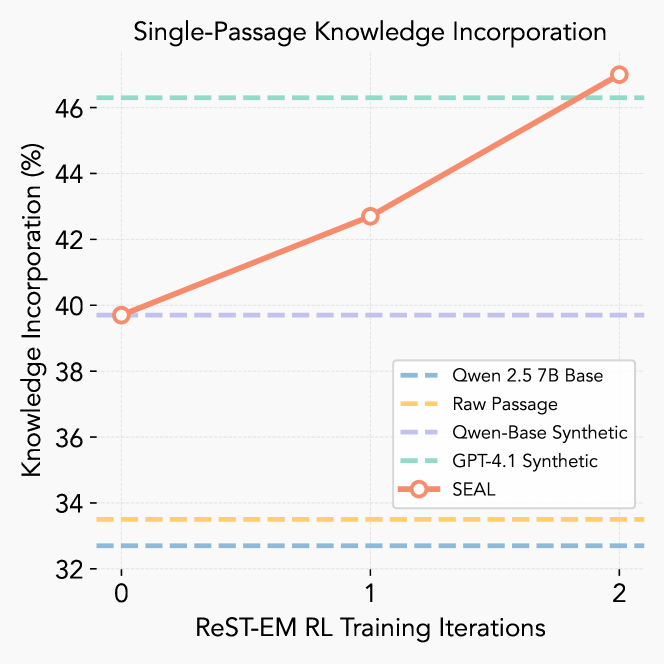
图 3 :强化学习迭代过程中的准确率变化。每轮迭代中包含一个 minibatch,含 50 个上下文,每个上下文采样 5 个自我编辑。在无上下文 SQuAD 任务上,SEAL 在两轮迭代后超过 GPT-4.1 数据。
| 方法 | 单段落 (n = 1) | 持续预训练 (n = 200) |
|---|---|---|
| 基础模型 | 32.7 | 32.7 |
| 段落微调 | 33.5 | 32.2 |
| 段落 + 自生成数据 | 39.7 | 41.0 |
| 段落 + GPT-4.1 数据 | 46.3 | 39.4 |
| SEAL | 47.0 | 43.8 |
表 2:知识融合任务在不同设置下的表现
这些结果表明,SEAL能够有效地将外部知识转化为模型可高效学习的内部表示,从而实现知识的持久内化,而非仅仅是上下文记忆。
3.2 少样本泛化:自主配置学习策略
在少样本泛化任务中,SEAL评估了模型在仅有少量示例的情况下,如何快速有效地适应全新任务的能力。SEAL的创新之处在于,它能够利用一套预定义的工具,自主选择数据增强方式和优化超参数,从而实现学习过程的自动化配置。
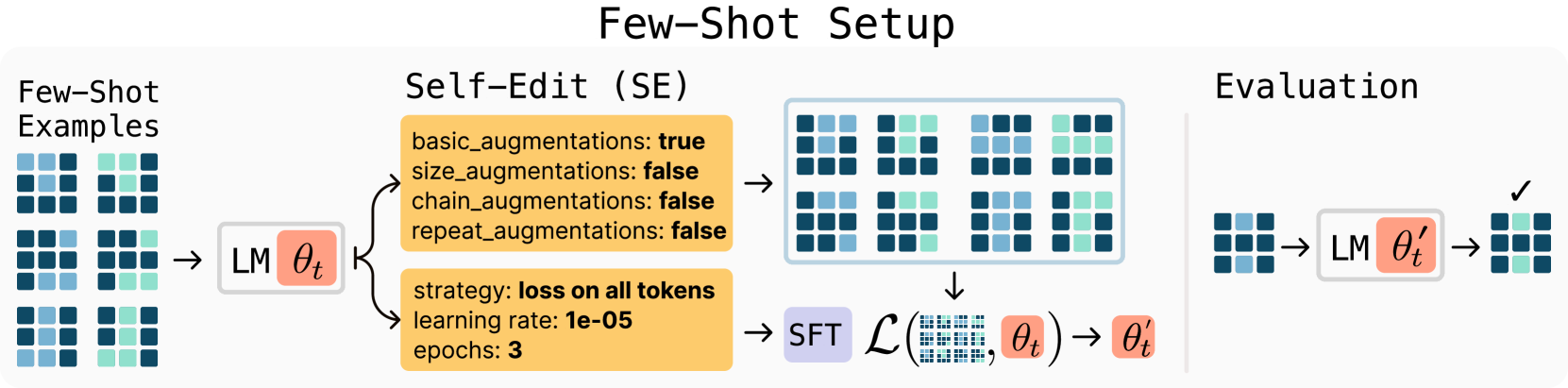
图 4 :SEAL 的小样本学习流程。 左:ARC 示例任务;中:模型生成包含数据增强方式与训练超参数的自我编辑;右:应用编辑后的模型在保留测试输入上进行评估。
实验对比了SEAL与多种基线方法(包括上下文学习ICL、未经RL训练的自我编辑TTT+Self-Edit (wo prior RL)以及最优人工配置的Oracle TTT)的性能:
| 方法 | 成功率 (%) |
|---|---|
| ICL | 0 |
| TTT + Self-Edit (wo prior RL) | 20 |
| SEAL | 72.5 |
| Oracle TTT | 100 |
- 大幅超越基线:SEAL在少样本抽象推理任务中的成功率达到了72.5%,远高于未经RL训练的自我编辑(20%)和标准上下文学习(0%)。这充分证明了SEAL通过RL训练,能够有效学习如何利用工具来优化少样本学习过程。
- 自主配置能力:SEAL能够根据任务特性,自主决定应用哪些数据增强(如旋转、翻转、缩放等)以及使用何种优化参数(如学习率、训练轮次、损失计算范围)。这种自动化配置能力极大地简化了少样本学习的复杂性,并提升了性能。
这些实验结果共同表明,SEAL是一个高度通用且强大的框架,它赋予了语言模型在面对新数据和新任务时,实现自我驱动、高效适应的革命性能力。
4 局限性与未来展望:迈向更智能、更自主的LLM
尽管SEAL展现出巨大的潜力,但作为一项前沿研究,目前仍存在一些值得深入探索的局限性,同时也为未来的研究指明了方向:
- 灾难性遗忘(Catastrophic Forgetting):当前SEAL在连续进行自我编辑时,仍可能出现对先前知识的灾难性遗忘现象。这意味着模型在学习新知识的同时,可能会遗忘旧知识。未来的工作可以探索通过更精细的奖励塑形(reward shaping)机制来惩罚对旧任务性能的下降,或整合更先进的持续学习(continual learning)策略(如零空间约束编辑或表征叠加)来缓解这一问题。
- 计算开销:SEAL的奖励循环涉及对整个模型进行微调和评估,这带来了显著的计算开销(每次自我编辑评估大约需要30-45秒)。未来的研究将致力于开发更高效的评估方法和优化策略,以降低计算成本,使其更具可扩展性。
- 上下文依赖评估:当前的SEAL实现要求每个上下文都与明确的下游任务配对,这限制了其在无标签语料库上的扩展性。一个富有前景的解决方案是让模型不仅生成自我编辑,还能自主生成评估问题(例如,为每个段落生成问答对或合成测试用例),从而在原始内容仍在上下文中时,为强化学习提供即时监督信号,拓宽其在通用训练领域的适用性。
展望未来,随着“数据墙”的日益临近(预计到2028年,前沿LLMs将训练完所有公开可用的人类生成文本),合成数据增强将变得前所未有的重要。SEAL为LLMs提供了一种生成高价值训练信号的独特能力,使其能够在数据受限的世界中实现自我学习和扩展。
我们设想一个未来场景:LLMs能够自主摄取新数据,并利用其现有知识和上下文数据,为自己生成大量的解释和推论。这种自我表达和自我完善的迭代循环将使模型即使在缺乏额外外部监督的情况下,也能在稀有或代表性不足的主题上持续改进。
此外,虽然现代推理模型通常通过RL训练来生成思维链(Chain-of-Thought, CoT)轨迹,但SEAL提供了一种互补的机制,允许模型学习何时以及如何更新自身的权重。这两种方法可以协同增效:模型可以选择在推理过程中进行权重更新以引导其当前轨迹,或在完成推理后将关键见解提炼到其参数中,从而通过内化学习改进未来的推理能力。
这种持续的自我完善循环对于构建智能体系统(Agentic Systems)也具有巨大的潜力。智能体模型需要在长时间的交互中运行,并动态适应不断演变的目标。SEAL的方法通过在交互后实现结构化的自我修改来支持这种行为:智能体可以合成一个自我编辑,触发权重更新。这将使智能体能够随着时间的推移而发展,使其行为与先前的经验保持一致,并减少对重复监督的依赖。
SEAL的提出,标志着大型语言模型不再是预训练后静态的存在。通过学习生成自身的合成自我编辑数据,并通过轻量级权重更新进行应用,它们能够自主地整合新知识并适应新任务。我们期待将SEAL框架扩展到预训练、持续学习和智能体模型中,最终使语言模型能够实现自我学习并在数据受限的世界中不断发展,开启LLM自我进化的新篇章。

留下评论