
[ICML 2024] SAMformer: 利用锐度感知最小化和通道注意力机制释放Transformer在时间序列预测中的潜力
| 标题 | SAMformer: Unlocking the Potential of Transformers in Time Series Forecasting with Sharpness-Aware Minimization and Channel-Wise Attention |
|---|---|
| 作者 | Romain Ilbert, Ambroise Odonnat, Vasilii Feofanov, Aladin Virmaux, Giuseppe Paolo, Themis Palpanas, Ievgen Redko |
| 邮箱 | romain.ilbert@hotmail.fr, ambroiseodonnattechnologie@gmail.com |
| 论文 | https://arxiv.org/abs/2402.10198v3 |
| 代码 | https://github.com/romilbert/samformer |
摘要
虽然Transformer在NLP和CV中大放异彩,但在多变量长期时间序列预测中却落后于简单的线性模型。本文从注意力机制的训练可行性入手,提出轻量但强大的SAMformer,实现参数更少但效果更佳。为了更好地理解这一现象,研究者们首先研究了一个玩具级线性预测问题,并证明尽管Transformer具有很高的表达能力,但它们无法收敛到真实解。研究进一步发现Transformer的注意力机制是导致其泛化能力低下的原因。基于这一观察,本文提出了一个浅层轻量级Transformer模型,当使用锐度感知优化(Sharpness-Aware Minimization, SAM)进行训练时,该模型能够成功逃离不良局部最小值。实验证明,这一结果适用于所有常用的真实世界多变量时间序列数据集。特别是,SAMformer超越了当前最先进的方法,并且与参数量更大的基础模型MOIRAI性能相当,同时具有显著更少的参数量。
1 引言
多变量时间序列预测是一个经典的学习问题,它通过分析时间序列来基于历史信息预测未来趋势。特别是,长期预测由于时间序列中的特征相关性和长期时间依赖性而异常具有挑战性。这一学习问题在许多现实世界应用中非常普遍,例如医疗数据、电力消耗、温度或股票价格等顺序收集的观测数据。
近年来,Transformer架构在NLP和视觉领域变得无处不在,在这两个领域都取得了突破性的性能。Transformer以其处理序列数据的高效性而闻名,这一特性自然而然地引起了人们对其在时间序列应用上的关注。不出所料,许多工作尝试提出针对时间序列的特定Transformer架构,以利用其捕获时间交互的能力。
然而,令人惊讶的是,当前多变量时间序列预测的最先进技术是由更简单的基于MLP的模型实现的,它显著优于基于Transformer的方法。此外,最近的研究发现,对于预测任务,线性网络可以与Transformer相媲美甚至更好,这让人质疑Transformer在这一领域的实用性。这一发现成为了本研究的起点。
现有方法的局限性
最近将Transformer应用于时间序列数据的工作主要集中在:(1)降低注意力机制的二次计算成本的高效实现,或(2)分解时间序列以更好地捕获其中的潜在模式。令人惊讶的是,这些工作都没有专门解决Transformer众所周知的训练不稳定问题,特别是在缺乏大规模数据的情况下。
本文贡献
本文的主要贡献如下:
-
通过研究一个简单的线性预测问题,揭示了Transformer在时间序列预测中的局限性,并证明了注意力机制是导致其泛化能力低下的主要原因;
-
提出了一个浅层轻量级Transformer模型SAMformer,它结合了时间序列预测中的最佳实践,如可逆实例归一化(RevIN)和最近在计算机视觉领域引入的通道注意力机制。研究表明,使用锐度感知最小化(SAM)优化这样一个简单的Transformer可以使其收敛到具有更好泛化能力的局部最小值;
-
通过在常用的多变量长期预测数据集上的实验,证明了所提方法的优越性。SAMformer超越了当前最先进的方法,并且与参数量更大的基础模型MOIRAI性能相当,同时具有显著更少的参数量。
2 方法
2.1 问题设置
在多变量时间序列预测中,我们考虑一个包含N个变量的时间序列,每个时间步都有一个观测值。给定过去L个时间步的观测值,任务是预测未来H个时间步的值。形式上,我们有一个输入序列$X ∈ ℝ^{L×N}$,目标是预测输出序列$Y ∈ ℝ^{H×N}$。
2.2 Transformer在线性预测问题中的局限性
尽管Transformer理论上能够表示任何函数,但研究发现,在这个简单的线性预测问题上,标准Transformer无法收敛到真实解。在多变量时间序列预测任务中,Transformer 的表现往往不如直接将输入投影到输出的简单线性神经网络。我们以这一观察为出发点,构建如下的生成模型,用于设计一个模拟时间序列预测任务的玩具回归问题:
\[Y=XW_{toy}+\epsilon \tag1\]其中,我们设定:$L = 512,H = 96,D = 7$,$W_{toy}∈ ℝ^{L×H}$ 是一个线性映射矩阵,$ε ∈ ℝ^{D×H}$ 是高斯噪声项。我们随机生成了 15000 个输入-目标对(其中 10000 个用于训练,5000 个用于验证),其中每个输入矩阵$X ∈ ℝ^{D×L}$的元素均为正态分布随机数。
在这个生成模型下,我们希望设计一个结构尽可能简洁、但仍能有效求解公式(1)问题的 Transformer 架构。为此,我们简化了标准的 Transformer 编码器结构:对输入 X 应用注意力机制,并将注意力输出与 X 残差连接相加;在此基础上,我们不再添加前馈神经网络模块,而是直接使用一个线性层进行输出预测。我们提出的模型定义如下:
\[f(\mathbf{X}) = [\mathbf{X} + \mathbf{A}(\mathbf{X})\mathbf{XW}_V\mathbf{W}_O]\mathbf{W} \tag2\]$W ∈ ℝ^{L×H}$,$W^V ∈ ℝ^{L×d_m}$,$W^O ∈ ℝ^{d_m×L}$,$A(X)$ 是对输入序列 $X ∈ ℝ^{D×L}$ 计算的注意力矩阵,其定义如下:
\[A(X) = \text{softmax}\left( \frac{X W^Q (W^K)^⊤ X^⊤}{\sqrt{d_m}} \right) ∈ ℝ^{D×D} \tag3\]接下来,我们希望明确注意力机制在解决公式(2)问题中扮演的角色。为此,我们设计了一个称为 Random Transformer 的模型,其中只有最终的线性参数 $W$ 会被优化,而注意力权重参数 $W^Q, W^K, W^V, W^O$ 在训练期间保持固定,并按 Glorot & Bengio(2010)方法初始化。此设定使模型等价于一个带随机映射的线性模型。最后,我们将两种模型(Transformer 与 Random Transformer)在训练优化后的局部最小值与Oracle 模型进行比较,Oracle 是对公式(1)采用最小二乘法的闭式解。
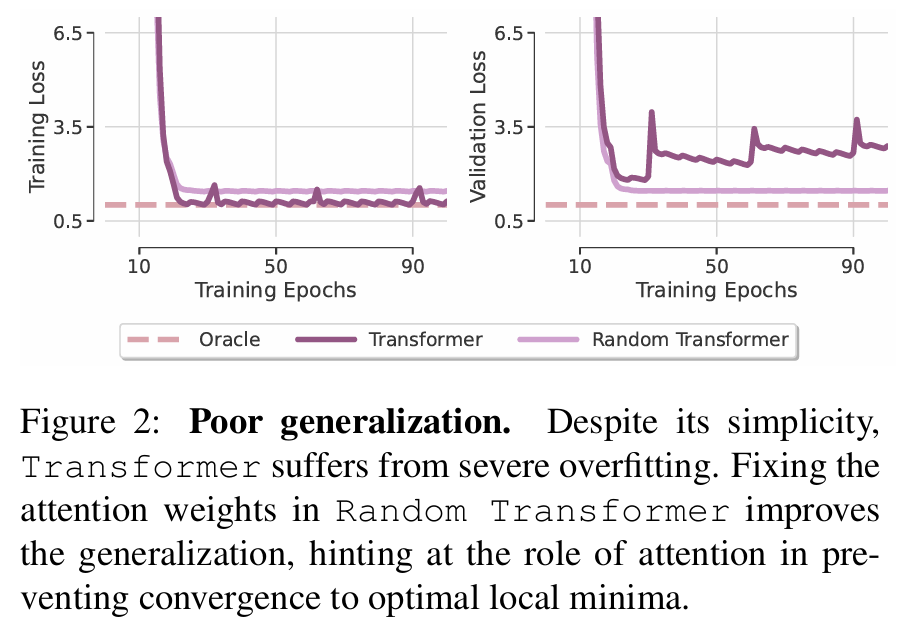 从Figure 2中可以看出,尽管结构简单,Transformer 仍然存在严重的过拟合问题。将注意力权重固定可以提升模型的泛化能力,这暗示了注意力机制可能在阻碍模型收敛到最优局部极小值中发挥了作用。当注意力权重固定时,这一问题有所缓解,但 Random Transformer 仍不理想。此外,由于 Random Transformer 与标准 Transformer 之间的参数量只相差约 2%,因此该现象也不能归因于过拟合问题。我们推断出:Transformer 泛化能力差的根本原因主要在于其注意力模块的可训练性问题。
从Figure 2中可以看出,尽管结构简单,Transformer 仍然存在严重的过拟合问题。将注意力权重固定可以提升模型的泛化能力,这暗示了注意力机制可能在阻碍模型收敛到最优局部极小值中发挥了作用。当注意力权重固定时,这一问题有所缓解,但 Random Transformer 仍不理想。此外,由于 Random Transformer 与标准 Transformer 之间的参数量只相差约 2%,因此该现象也不能归因于过拟合问题。我们推断出:Transformer 泛化能力差的根本原因主要在于其注意力模块的可训练性问题。
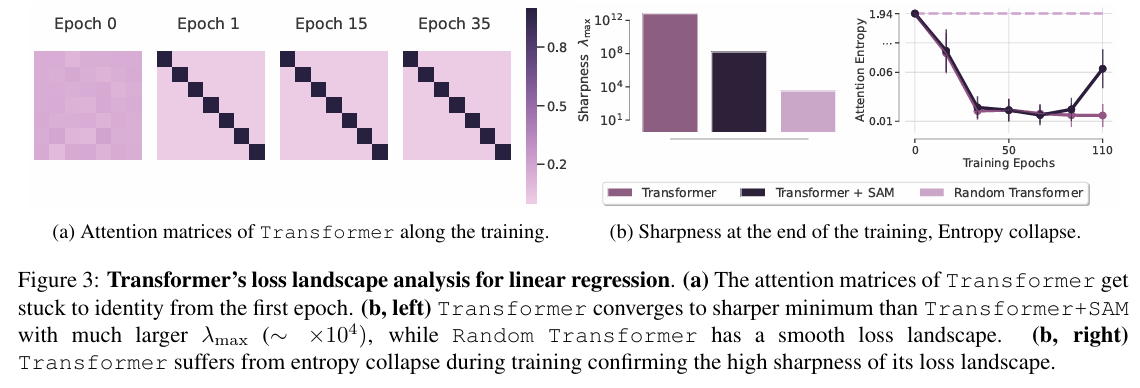
Figure 3是Transformer 的线性回归损失分析。 (a) Transformer 的注意力矩阵在训练过程中从第一轮开始就陷入了恒等映射。 (b, 左) Transformer 收敛到比 Transformer + SAM 更尖锐的极小值,其最大特征值 $\lambda_{max}$ 明显更大(约为 ×10⁴),而 Random Transformer 则具有更平滑的损失景观。 (b, 右) Transformer 在训练过程中出现熵塌陷,验证了其损失景观的高度尖锐性。
2.3 SAMformer:结合锐度感知最小化和通道注意力的Transformer
基于上述发现,本文提出了SAMformer,一个专为时间序列预测设计的浅层轻量级Transformer模型。
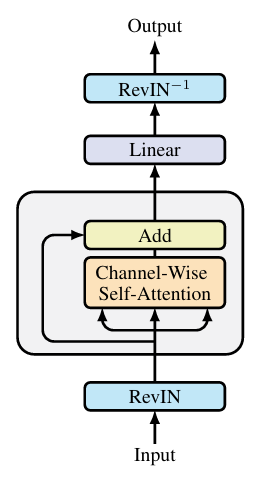
SAMformer的主要创新点包括:
-
锐度感知最小化(SAM):传统的深度学习优化方法往往会导致模型收敛到泛化性能差的锐利局部最小值。SAM通过寻找损失函数平坦区域的最小值,提高了模型的泛化能力。具体来说,SAM在每次参数更新时,不仅考虑当前点的损失,还考虑参数空间邻域内的最大损失。
-
通道注意力机制:与标准Transformer的多头自注意力不同,SAMformer采用了通道注意力机制,这种机制更适合处理多变量时间序列数据。通道注意力允许模型在不同变量(通道)之间建立关联,同时保持时间维度上的局部性。
-
可逆实例归一化(RevIN):为了处理时间序列数据中常见的分布偏移问题,SAMformer采用了RevIN,这是一种专为时间序列设计的归一化技术。RevIN在训练过程中对输入进行归一化,并在预测阶段逆转这一过程,有效地处理了分布偏移问题。
3 实验
实验用了多个标准多变量时间序列预测数据集,包括:ETT数据集、天气数据集、电力消耗数据集、交通流量数据集。
SAMformer与多种基准模型进行了比较,包括:线性模型(如AutoARIMA)、基于MLP的模型(如PatchTST)、基于RNN的模型(如LSTNet)、基于CNN的模型(如SCINet)、基于Transformer的模型(如Informer、Autoformer)、大型基础模型(如MOIRAI)。
实验结果表明,SAMformer在大多数数据集和预测长度上都优于现有方法。
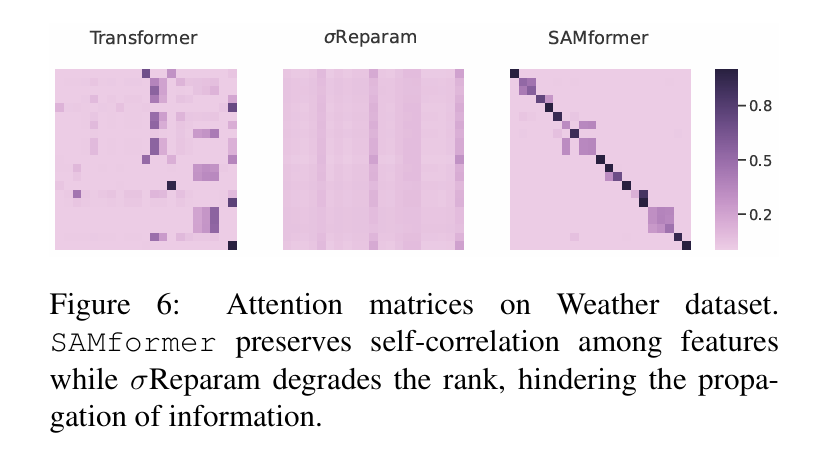
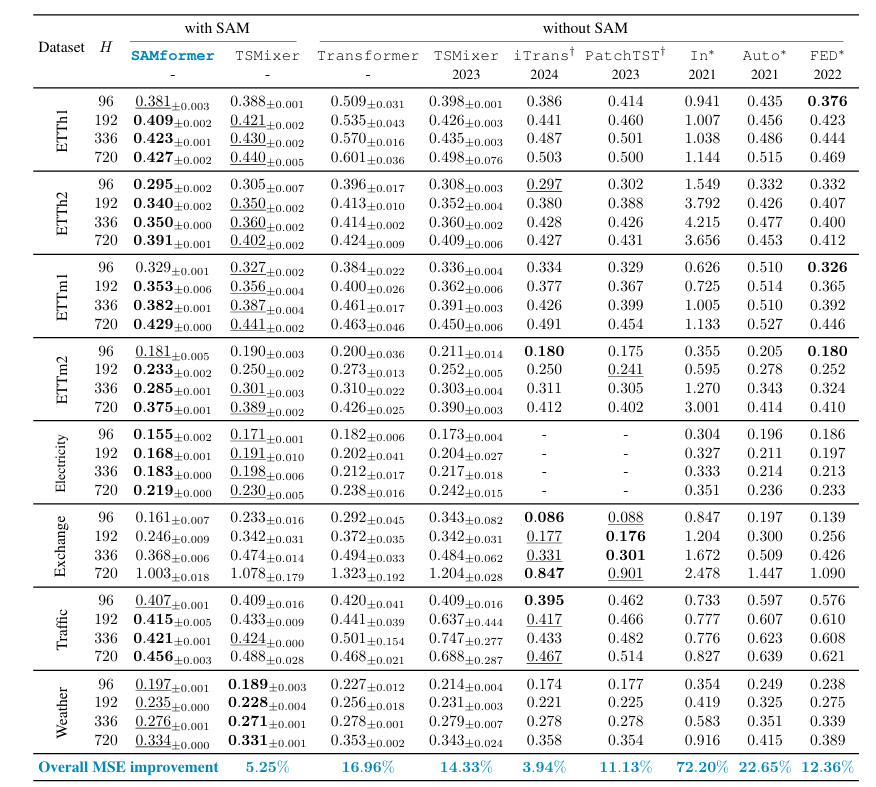
SAMformer 模型在多元时间序列预测任务中展现了卓越的性能和实用性。实验结果表明,SAMformer 在多个常用的公开数据集上均取得了领先的成果,显著优于包括 TSMixer 和其他主流基于 Transformer 的方法在内的现有基准模型。具体而言,SAMformer 不仅在预测精度上实现了大幅提升,例如相较于 TSMixer 提升了14.33%,相较于表现最佳的多元 Transformer 模型 FEDformer 提升了12.36%,并且也优于普通的 Transformer 模型达16.96%。
除了预测精度上的优势,SAMformer 还表现出一系列理想的定性特征。其损失函数的地貌更为平滑,这得益于锐度感知最小化(SAM)优化策略的应用,从而增强了模型的泛化能力和对不同随机初始化的鲁棒性,确保了在多次实验中性能的一致性和稳定性。模型架构方面,SAMformer 采用了轻量化的单层单头注意力设计,使其参数量远少于 TSMixer(平均少约4倍),在计算效率上具有明显优势,同时其统一的架构在不同数据集和预测长度下均表现良好,减少了超参数调优的复杂性。其核心的通道注意力机制被证明能够有效捕捉特征间的自相关性,表现出结构良好的对角注意力模式,优于传统的注意力机制以及简单的固定注意力(如单位矩阵)。
4 结论
本研究揭示了Transformer在时间序列预测中的局限性,并提出了SAMformer作为解决方案。通过结合锐度感知最小化和通道注意力机制,SAMformer成功地释放了Transformer在时间序列预测中的潜力。实验结果表明,SAMformer不仅超越了现有的最先进方法,还与参数量更大的基础模型性能相当。
这项工作为时间序列预测领域提供了新的见解和方法,同时也为Transformer在其他领域的应用提供了启示。未来的工作可以探索SAMformer在更多时间序列任务中的应用,以及进一步改进模型架构和优化方法。

留下评论